Материалы по тегу: instinct
|
07.12.2023 [16:54], Сергей Карасёв
GigaIO создаст уникальное ИИ-облако с тысячами ускорителей AMD Instinct MI300XКомпания GigaIO объявила о заключении соглашения по созданию инфраструктуры для специализированного ИИ-облака TensorNODE, которое создаётся провайдером TensorWave. В составе платформы будут применяться ускорители AMD Instinct MI300X, оснащённые 192 Гбайт памяти HBM3. Основой TensorNODE послужат мини-кластеры SuperNODE, дебютировавшие летом уходящего года. Особенность этого решения заключается в том, что оно позволяет связать воедино 32 и даже 64 ускорителя посредством распределённого интерконнекта на базе PCI Express. TensorWave будет использовать FabreX для формирования пулов памяти петабайтного масштаба. На первом этапе в начале 2024 года платформа TensorNODE объединит до 5760 ускорителей Instinct MI300X в одном домене. Таким образом, при решении сложных задач можно будет получить доступ более чем к 1 Пбайт памяти с любого узла. Это, как отмечается, позволит обрабатывать даже самые ресурсоёмкие нагрузки в рекордно короткие сроки. 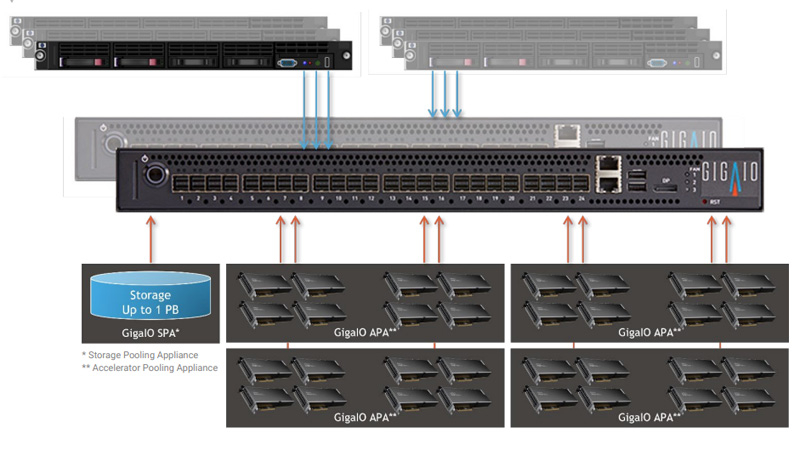
Источник изображения: GigaIO В течение следующего года планируется развернуть несколько систем TensorNODE. Архитектура GigaIO обеспечит улучшенную гибкость по сравнению с традиционными решениями: инфраструктуру можно будет оптимизировать «на лету» для удовлетворения как текущих, так и будущих потребностей в области ИИ и больших языковых моделей (LLM). Отмечается, что TensorNODE полностью базируется на ключевых компонентах AMD. Помимо ускорителей Instinct MI300X, это процессоры EPYC Genoa. Облако TensorWave обеспечит снижение энергозатрат и общей стоимости владения благодаря исключению из конфигурации избыточных серверов и связанного с ними сетевого оборудования.
16.11.2023 [15:29], Сергей Карасёв
В Microsoft Azure появились инстансы ND MI300X v5 с восемью ускорителями AMD Instinct и процессорами Intel XeonКомпания Microsoft анонсировала инстансы Azure ND MI300X v5 на основе ускорителей AMD Instinct MI300X, представленных летом нынешнего года. Эти ВМ ориентированы на ресурсоёмкие ИИ-нагрузки, в частности, на решение задач инференса. Изделия Instinct MI300X несут на борту 192 Гбайт памяти HBM3 с пропускной способностью до 5,2 Тбайт/с. В составе одной виртуальной машины ND MI300X v5 объединены восемь ускорителей, соединённых между собой посредством Infinity Fabric 3.0, а с хостом — по PCIe 5.0. В сумме это даёт 1,5 Тбайт памяти HBM3, что, как отмечает Microsoft, является самой большой ёмкостью HBM, доступной в облаке. Виртуальные машины Azure ND — это дополнение к семейству решений на базе GPU, такие машины специально предназначены для рабочих нагрузок ИИ и глубокого обучения. Microsoft подчёркивает, что в случае ND MI300X v5 используется та же аппаратная платформа, которая применяется и для других ВМ семейства. Она включает процессоры Intel Xeon Sapphire Rapids, 16 каналов оперативной памяти DDR5, а также подключение NVIDIA Quantum-2 CX7 InfiniBand с пропускной способностью 400 Гбит/с на каждый ускоритель и 3,2 Тбит/с на виртуальную машину. 
Источник изображения: AMD По заявлениям Microsoft, на базе ND MI300X v5 могут запускаться самые крупные модели ИИ. Клиенты могут быстро перейти на новые инстансы с других решений серии ND благодаря тому, что открытая платформа AMD ROCm содержит все библиотеки, компиляторы, среды выполнения и инструменты, необходимые для ускорения ресурсоемких приложений.
15.11.2023 [13:57], Сергей Карасёв
Французский суперкомпьютер Adastra одним из первых получит новейшие ускорители AMD Instinct MI300AФранцузское национальное агентство по высокопроизводительным вычислениям (GENCI), по сообщению HPCwire, проводит масштабное обновление суперкомпьютера Adastra, о запуске которого было объявлено два года назад. После апгрейда система сможет решать сложные задачи в области ИИ. Комплекс Adastra находится под управлением Национального вычислительного центра высшего образования Франции (CINES). Система использует платформу HPE Cray EX235A с оптимизированными процессорами AMD EPYC Milan (64 ядра; 2,0 ГГц) и ускорителями AMD Instinct MI250X. Апгрейд предусматривает использование гибридных чипов Instinct MI300A в составе платформы HPE Cray EX4000, оснащённой 14 серверами HPE Cray EX255a Accelerator Blade. В общей сложности будут задействованы 28 узлов, каждый из которых содержит четыре чипа Instinct MI300A. Таким образом, суммарное количество использованных изделий Instinct MI300A равно 112. Задействован 200G-интерконнект HPE Slingshot 11. 
Изображение: GENCI Об итоговой производительности обновлённого суперкомпьютера Adastra данных пока нет. Но в прежнем виде система занимает 17-ю строку в ноябрьском рейтинге TOP500 с быстродействием 46,1 Пфлопс (FP64). А в мировом рейтинге самых энергоэффективных НРС-систем GREEN500 комплекс Adastra находится на третьей позиции с показателем 58,021 Гфлопс/Вт.
22.10.2023 [14:06], Сергей Карасёв
Видео дня: строительство 2-Эфлопс суперкомпьютера El CapitanЛиверморская национальная лаборатория им. Э. Лоуренса (LLNL) Министерства энергетики США опубликовала видео (см. ниже), демонстрирующее процесс сборки вычислительного комплекса El Capitan, которому предстоит стать самым мощным суперкомпьютером мира. В текущем рейтинге TOP500 лидирует система Frontier, установленная в Национальной лаборатории Окриджа (ORNL), также принадлежащей Министерству энергетики США. Быстродействие Frontier достигает 1,194 Эфлопс. Суперкомпьютер El Capitan сможет демонстрировать производительность более 2 Эфлопс (FP64). Сборка комплекса началась в июле нынешнего года, а ввод в эксплуатацию запланирован на середину 2024-го. Стоимость проекта оценивается приблизительно в $600 млн. В основе El Capitan — платформа HPE Cray Shasta. Применена гибридная архитектура AMD с APU Instinct MI300A: изделие содержит 24 ядра с микроархитектурой Zen 4 общего назначения, блоки CDNA 3 и 128 Гбайт памяти HBM3. 
Источник изображения: LLNL Отмечается, что в проекте El Capitan задействованы сотни сотрудников LLNL и отраслевых партнёров. Суперкомпьютер состоит из тысяч вычислительных узлов и требует столько же энергии, сколько город среднего размера. В течение нескольких лет специалисты готовили инфраструктуру для El Capitan, создавая подсистемы электропитания и охлаждения, устанавливая компоненты и монтируя сетевые соединения. После запуска суперкомпьютер будет использоваться для решения задач в сферах ядерной энергетики, национальной безопасности, здравоохранения, изменений климата и пр.
29.09.2023 [23:55], Алексей Степин
Без CUDA никуда? ИИ-стартап Lamini полагается исключительно на ускорители AMD InstinctКогда речь заходит о больших языковых моделях (LLM), то чаще всего подразумевается их обучение, дообучение и запуск на аппаратном обеспечении NVIDIA, как наиболее широко распространённом и лучше всего освоенном разработчиками. Но эта тенденция понемногу меняется — появляются либо специфические решения, могущие поспорить в эффективности с ускорителями NVIDIA, либо разработчики осваивают другое «железо». К числу последних принадлежит ИИ-стартап Lamini, сделавший ставку на решения AMD: ускорители Instinct и стек ROCm. Главным продуктом Lamini должна стать программно-аппаратная платформа Superstation, позволяющая создавать и развёртывать проекты на базе генеративного ИИ, дообучая базовые модели на данных клиента. 
Изображения: Lamini Напомним, ROCm представляет собой своего рода аналог NVIDIA CUDA, но упор в решении AMD сделан на более широкую поддержку аппаратного обеспечения, куда входят не только ускорители и GPU, но также CPU и FPGA — всё в рамках инициативы Unified AI Stack. К тому же в этом году у ROCm появилась интеграция с популярнейшим фреймворком PyTorch, который в версии 2.0 получил поддержку ускорителей AMD Instinct.  Что же касается Lamini и её проекта, то, по словам основателей, он привлёк внимание уже более 5 тыс. потенциальных клиентов. Интерес к платформе проявили, например, Amazon, Walmart, eBay, GitLab и Adobe. В настоящее время платформа Lamini уже более года работает на кластере, включающем в себя более 100 ускорителей AMD Instinct MI250, и обслуживает клиентов. При этом заявляется возможность масштабирования до «тысяч таких ускорителей». Более того, AMD сама активно пользуется услугами Lamini.  На данный момент это единственная LLM-платформа, целиком работающая на аппаратном обеспечении AMD, при этом стоимость запуска на ней ИИ-модели Meta✴ Llama 2 с 70 млрд параметров, как сообщается, на порядок дешевле, нежели в облаке AWS. Солидный объём набортной памяти (128 Гбайт) у MI250 позволяет разработчикам запускать более сложные модели, чем на A100. Согласно тестам, проведённым Lamini для менее мощного ускорителя AMD Instinct MI210, аппаратное обеспечение «красных» способно демонстрировать в реальных условиях до 89% от теоретически возможного в тесте GEMM и до 70% от теоретической пропускной способности функции ROCm hipMemcpy. Выбор Lamini несомненно принесёт AMD пользу в продвижении своих решений на рынке ИИ. К тому же в настоящее время они более доступны, чем от NVIDIA H10. Сама AMD объявила на мероприятии AI Hardware Summit, что развитие платформы ROCm в настоящее время является приоритетным для компании.
02.08.2023 [16:46], Руслан Авдеев
AMD готовит специальные ИИ-ускорители для Китая, которые не будут подпадать под санкции СШАПродажу классических видеокарт в Китай пока никто не запрещал, но на рынке ускорителей вычислений ситуация совсем иная. Как сообщает Tom’s Hardware, ужесточение США антикитайских санкций привело к тому, что NVIDIA и Intel пришлось выпускать для местного рынка модели с ухудшенными характеристиками, а теперь их примеру последует AMD. По словам главы компании Лизы Су (Lisa Su), хотя AMD твёрдо намерена придерживаться антикитайских санкций, выгоду она упускать не собирается. Как заявила Су, компания разработает ИИ-ускорители специально для китайских покупателей. Хотя подробными планами глава AMD не поделилась, весьма вероятно, что компания поступит, как и её конкуренты, искусственно ухудшив характеристики уже имеющихся или находящихся в разработке ускорителей. В частности, речь может идти об ускорителях серии Instinct MI. Не исключено, что появится специальная версия новейшего Instinct MI300, чья премьера запланирована только на IV квартал 2023 года. Поскольку бум ИИ-технологий продолжается, решение AMD заняться выпуском ускорителей для китайского рынка стало вполне оправданным. Например, именно благодаря растущему спросу на ИИ-решения NVIDIA стала первым производителем чипов с рыночной капитализацией, перевалившей за $1 трлн, причём по итогам I квартала 2024 финансового года 60 % выручки пришлось на продукты для ЦОД, включая ускорители для ИИ и HPC-систем. 
Источник изображения: AMD Хотя США всеми силами стремится ограничить технологическое развитие ИИ-систем Китая, вводя всё новые экспортные ограничения, компании вроде NVIDIA и Intel пока довольно успешно обходят ограничения, ухудшая свои продукты. В частности, скорость внутреннего интерконнекта в продуктах, поставляемых в Китай, не должна превышать 600 Гбайт/с. Вариант NVIDIA A100, продающийся на китайском рынке под именем A800, «замедлен» с запасом — до 400 Гбайт/с. То же касается и модели H800 — клона H100, урезанного не только по шине, но и по производительности. При этом даже версии с ограничениями позволяют хорошо заработать в Китае — H800 продаётся в Поднебесной по цене до $70 тыс. за штуку. К уловкам прибегает и компания Intel. Например, недавно она представила ИИ-ускоритель Habana Gaudi 2 для китайских покупателей. Другими словами, хотя AMD слегка опаздывает в гонке на рынке ускорителей, компания вполне может рассчитывать на хороший спрос в том числе, у китайских партнёров. Пока трудно предсказать, не вызовет ли спрос на чипы для ИИ такую же «золотую лихорадку», как и та, что возникла на рынке видеокарт после появления криптовалют. Как сообщает Tom’s Hardware, имеются ранние признаки того, что ИИ-компании начали скупать высокопроизводительные видеокарты.
23.07.2023 [14:57], Сергей Карасёв
ВМС США обзаведутся 17,7-Пфлопс суперкомпьютером Blueback с ускорителями AMD Instinct MI300AМинистерство обороны США (DoD) объявило о планах по развёртыванию новой суперкомпьютерной системы в рамках Программы модернизации высокопроизводительных вычислений (HPCMP). Комплекс получил название Blueback — в честь американской подводной лодки USS Blueback (SS-581). Сообщается, что Blueback расположится в Центре суперкомпьютерных ресурсов в составе DoD (Navy DSRC), который находится в ведении Командования морской метеорологии и океанографии (CNMOC). Суперкомпьютер заменит три старых вычислительных комплекса в экосистеме HPCMP. Основой Blueback послужит платформа HPE Cray EX4000. Архитектура включает процессоры AMD EPYC Genoa, 128 гибридных ускорителей AMD Instinct MI300A (APU) и 24 ускорителя NVIDIA L40, связанных между собой 200G-интерконнектом Cray Slingshot-11. В состав комплекса войдёт Lustre-хранилище Cray ClusterStor E1000 вместимостью 20 Пбайт, включая 2 Пбайт пространства на базе SSD NVMe. Объём системной памяти — 538 Тбайт. Общее количество вычислительных ядер будет достигать 256 512. 
Источник изображения: Jonathan Holloway / DoD Ожидается, что суперкомпьютер Blueback будет введён в эксплуатацию в 2024 году. Кстати, совсем недавно центр Navy DSRC получил НРС-систему Nautilus производительностью 8,2 Пфлопс. Она содержит 176 128 ядер и 382 Тбайт памяти.
13.07.2023 [23:49], Алексей Степин
Младший напарник El Capitan: кластер Tuolumne будет использоваться для открытых исследованийЛиверморская национальная лаборатория (LLNL) вовсю ведёт монтаж суперкомпьютера El Capitan, мощность которого превзойдёт 2 Эфлопс. Дебютирует новая система в середине следующего года. Однако это не единственный суперкомпьютер LLNL. Помимо тестовых кластеров rzVernal, Tioga и Tenay, в строй будет введён и машина Tuolumne производительностью более 200 Пфлопс. El Capitan получит уникальные серверные APU AMD Instinct MI300A, содержащие 24 ядра Zen 4 и массив ускорителей с архитектурой CDNA3, дополненный собственным стеком памяти HBM3 объёмом 128 Гбайт. El Capitan будет использоваться в том числе для секретных и закрытых проектов, но, как сообщают зарубежные источники, кластер Tuolumne на базе той же аппаратной платформы HPE станет открытой платформой, практически самой мощной в своём классе. 
Тестовые стойки в ЦОД LLNL Сообщается о том, что производительность Tuolumne составит около 15 % от таковой у El Capitan, то есть от 200 до 300 Пфлопс. Хотя это не позволяет отнести Tuolumne к экза-классу, такие цифры позволяют претендовать на вхождении в первую пятёрку рейтинга TOP500. Впервые имя Tuolumne было упомянуто в 2021 году, когда речь шла о системе раннего доступа RZNevada, целью которой была тестирование и отработка аппаратного и программного стеков El Capitan. Также известно, что система охлаждения и питания в главном ЦОД LLNL была модернизирована, в результате чего её мощность выросла с 85 до 100 МВт, и часть этих мощностей достанется Tuolumne. Правда, когда суперкомпьютер будет введён в строй, не говорится.
06.07.2023 [20:49], Владимир Мироненко
Начата сборка 2-Эфлопс суперкомпьютера El Capitan на базе серверных APU AMD Instinct MI300AЛиверморская национальная лаборатория (LLNL) объявила о получении первой партии компонентов суперкомпьютера El Capitan, которые сразу же начала устанавливать. Система будет запущена в середине 2024 года и, согласно данным LLNL, будет обеспечивать производительность более 2 Эфлопс. Стоимость El Capitan составляет около $600 млн. El Capitan будет использоваться для выполнения задач лабораторий Национальной администрации по ядерной безопасности США, чтобы они «могли поддерживать уверенность в национальных силах ядерного сдерживания», — сообщила LLNL. «На момент принятия проекта в следующем году El Capitan, вероятно, станет самым мощным суперкомпьютером в мире», — указано в заявлении LLNL. Он заменит машину Sierra на базе IBM POWER 9 и NVIDIA Volta, обойдя её производительности более чем на порядок. 
Источник изображений: LLNL El Capitan базируется на платформе HPE Cray Shasta, как и две другие экзафлопсные системы, Frontier и Aurora. В отличие от этих систем, использующих традиционную конфигурацию дискретных CPU и ускорителей, El Capitan станет первым суперкомпьютером на базе гибридной архитектуры AMD. APU Instinct MI300A включает 24 ядра с микроархитектурой Zen 4 общего назначения, блоки CDNA 3 и 128 Гбайт памяти HBM3. Правда, пока не уточняется, устанавливаются ли узлы уже с финальной конфигурации «железа» или же пока что предсерийные образцы. 
04.07.2023 [17:20], Владимир Мироненко
Обойдёмся без NVIDIA: MosaicML перенесла обучение ИИ на ускорители AMD Instinct MI250 без модификации кодаРазработчик решений в области генеративного ИИ MosaicML, недавно перешедший в собственность Databricks, сообщил о хороших результатах в обучении больших языковых моделей (LLM) с использованием ускорителей AMD Instinct MI250 и собственной платформы. Компания рассказала, что подыскивает от имени своих клиентов новое «железо» для машинного обучения, поскольку NVIDIA в настоящее время не в состоянии обеспечить своими ускорителями всех желающих. MosaicML пояснила, что требования к таким чипам просты:

Источник изображений: MosaicML Как отметила компания, ни один из чипов до настоящего времени смог полностью удовлетворить все требования MosaicML. Однако с выходом обновлённых версий фреймворка PyTorch 2.0 и платформы ROCm 5.4+ ситуация изменилась — обучение LLM стало возможным на ускорителях AMD Instinct MI250 без изменений кода при использовании её стека LLM Foundry. 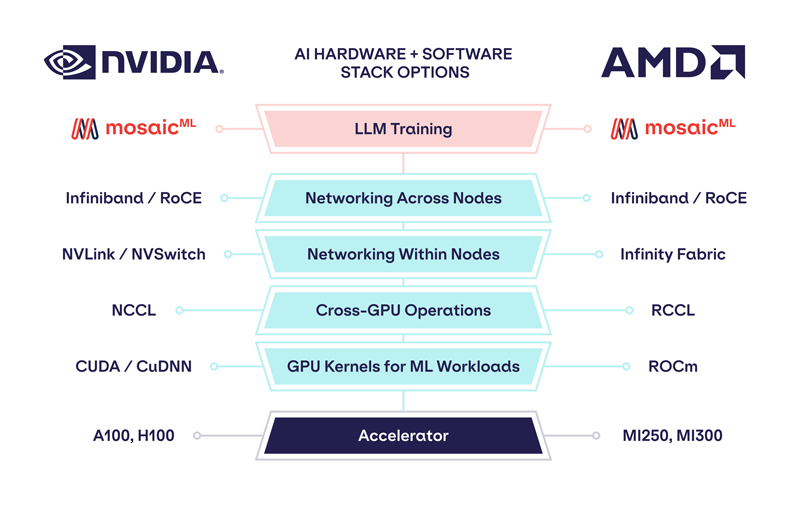 Некоторые основные моменты:
При этом никаких изменений в коде не потребовалось. 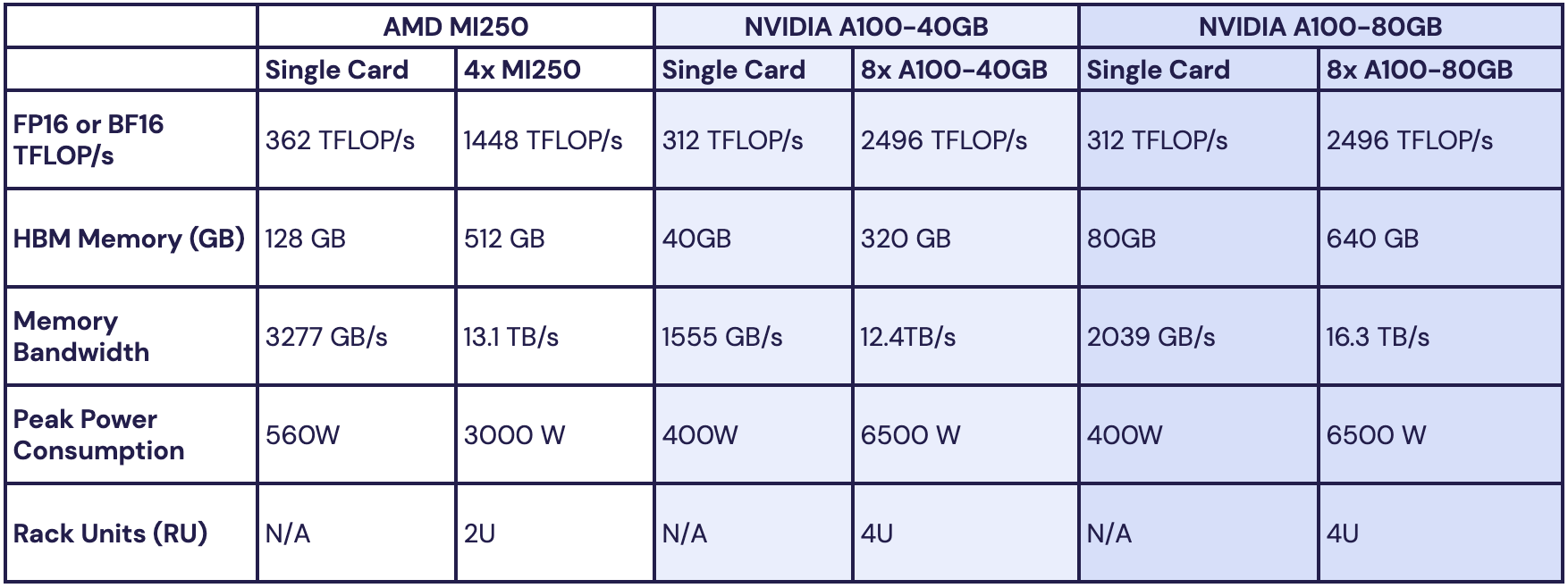 Все результаты получены на одном узле из четырёх MI250, но компания работает с гиперскейлерами для проверки возможностей обучения на более крупных кластерах AMD Instinct. «В целом наши первоначальные тесты показали, что AMD создала эффективный и простой в использовании программно-аппаратный стек, который может конкурировать с NVIDIA», — сообщила MosaicML. Это важный шаг в борьбе с доминирующим положением NVIDIA на рынке ИИ. |
|

