Материалы по тегу: hopper
|
28.08.2022 [16:25], Алексей Степин
NVIDIA поделилась подробностями об ускорителях H100 на базе архитектуры HopperНа конференции Hot Chips 34 NVIDIA поделилась новыми подробностями о грядущих ускорителях H100 на базе архитектуры Hopper. Чип GH100 содержит 80 млрд транзисторов и производится с использованием специально оптимизированного для нужд NVIDIA техпроцесса TSMC N4, созданного в содружестве с NVIDIA. Ускоритель первым в мире получит память HBM3. В составе чипа есть сразу 144 потоковых мультипроцессоров (SM), что несколько больше, нежели в A100, где таких блоков физически 128. Активных блоков же всего 132, но NVIDIA заявляет о вдвое более высокой производительности новых SM при сравнении с прошлым поколением при равной частоте. Это относится как к модулям FP32, так и FP64 FMA. В дополнение появилась поддержка формата FP8, всё чаще встречающегося в сценариях машинного обучения, не требующих высокой точности вычислений. 
Здесь и далее источник изображений: NVIDIA via ServeTheHome В этом режиме NVIDIA поддержала оба наиболее распространённых формата FP8: E5M2 и E4M3, то есть представление числа в форме 5 или 4 бита экспоненту и 2 или 3 бита на мантиссу соответственно. Каждый тензорный блок FP8 обеспечивает перемножение двух матриц в формате FP8 с дальнейшим накоплением и преобразованием результата, но самое важное здесь то, что благодаря наличию нового блока Transformer Engine выбор наиболее подходящего варианта FP8 осуществляется автоматически. Если верить NVIDIA, усовершенствованная архитектура тензорных процессоров с поддержкой FP8 позволяет добиться точности, сопоставимой с FP16, но при вдвое более высокой производительности и вдвое меньшем расходе памяти. 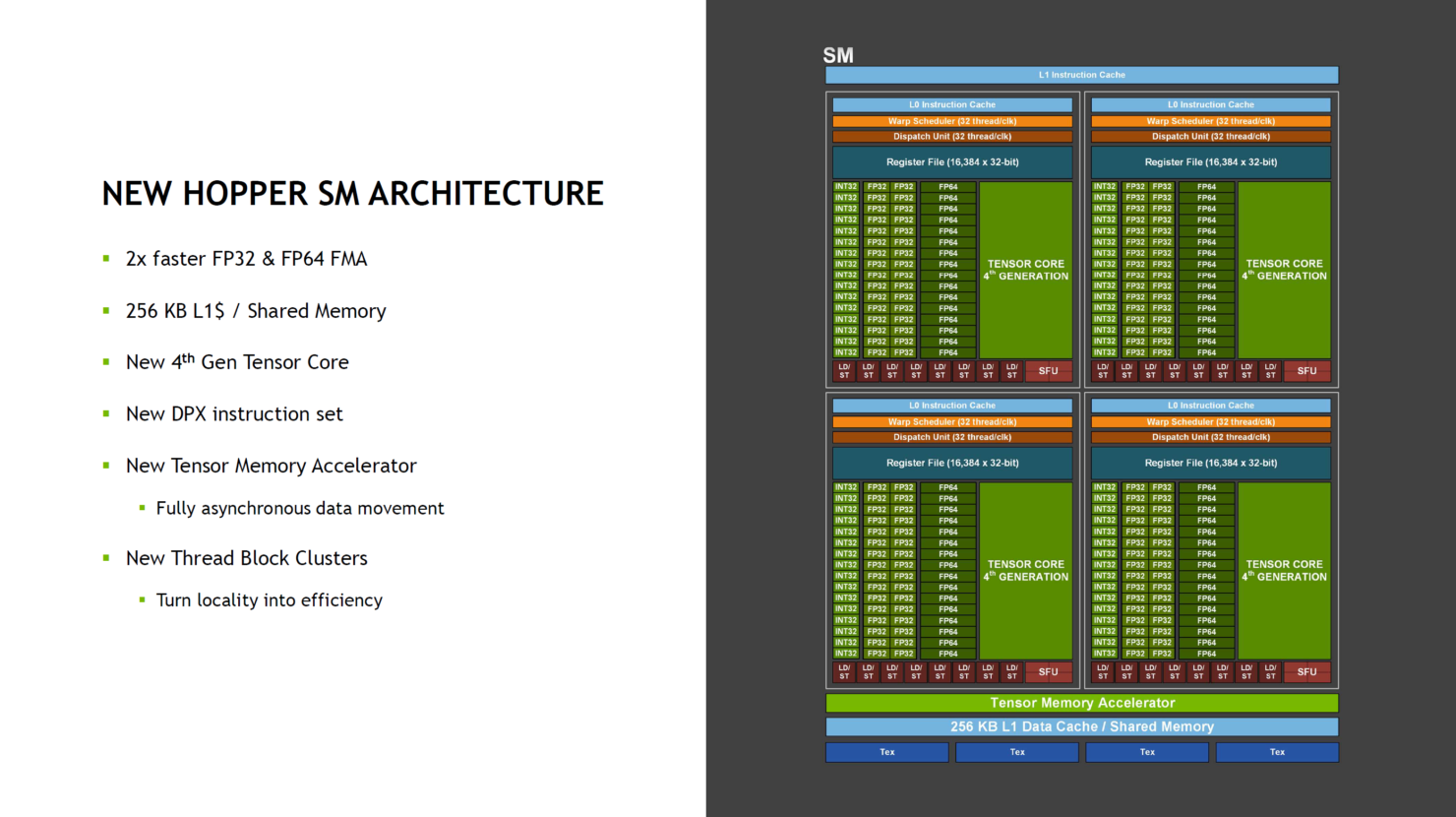 Всего каждом блоке SM имеется 128 модулей FP32, по 64 модуля INT32 и FP64 и по 4 тензорных ядра, а также тензорный ускоритель работы с памятью и общий L1-кеш объёмом 256 Кбайт. Объём L2-кеша составляет целых 50 Мбайт. В текущей реализации доступно 16896 CUDA-ядер из 18432 возможных и 528 тензорных ядер из 576. Вдвое быстрее, по словам NVIDIA, стали и новые модули тензорных вычислений, относящиеся уже к четвертому поколению. Внедрена поддержка нового набора инструкций DPX, появилась поддержка асинхронности при перемещении данных и т.д. 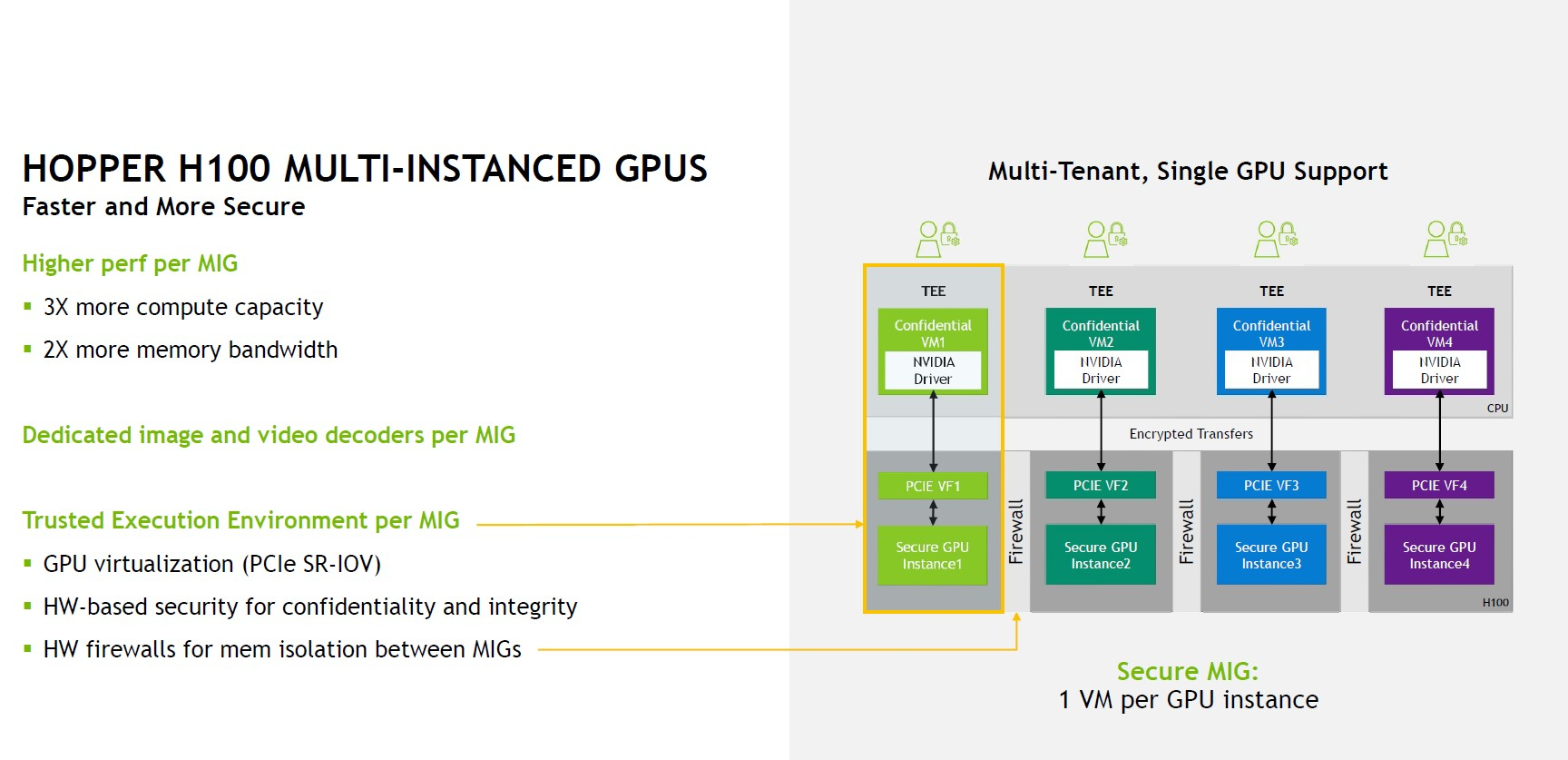 До второго поколения подросла технология MIG (Multi-instance GPU). Теперь на каждый такой виртуальный ускоритель стало приходиться в три раза больше вычислительных мощностей и в два раза — пропускной способности памяти. Последнее достигнуто благодаря применению HBM3. В данном варианте применены сборки HBM3 объёмом 16 Гбайт каждая (5120-бит шина). Пять сборок дают 80 Гбайт локальной памяти с ПСП 3 Тбайт/с. Посадочных мест для сборок шесть, но одно используется только для выравнивания высоты чипа  При этом виртуализация у GH100 полная, насколько это вообще возможно: обеспечена поддержка доверенных вычислений на аппаратном уровне, включая специализированные блоки брандмауэров, обеспечивающих изоляцию регионов памяти каждого vGPU, а также блоки проверки целостности и поддержки конфиденциальности данных. О поддержке нового поколения интерконнекта NVLink 4 мы рассказывали ранее — этот интерфейс даёт до 900 Гбайт/с для объединения нескольких чипов и ускорителей, но, главное, предоставляет гибкие возможности масштабирования. 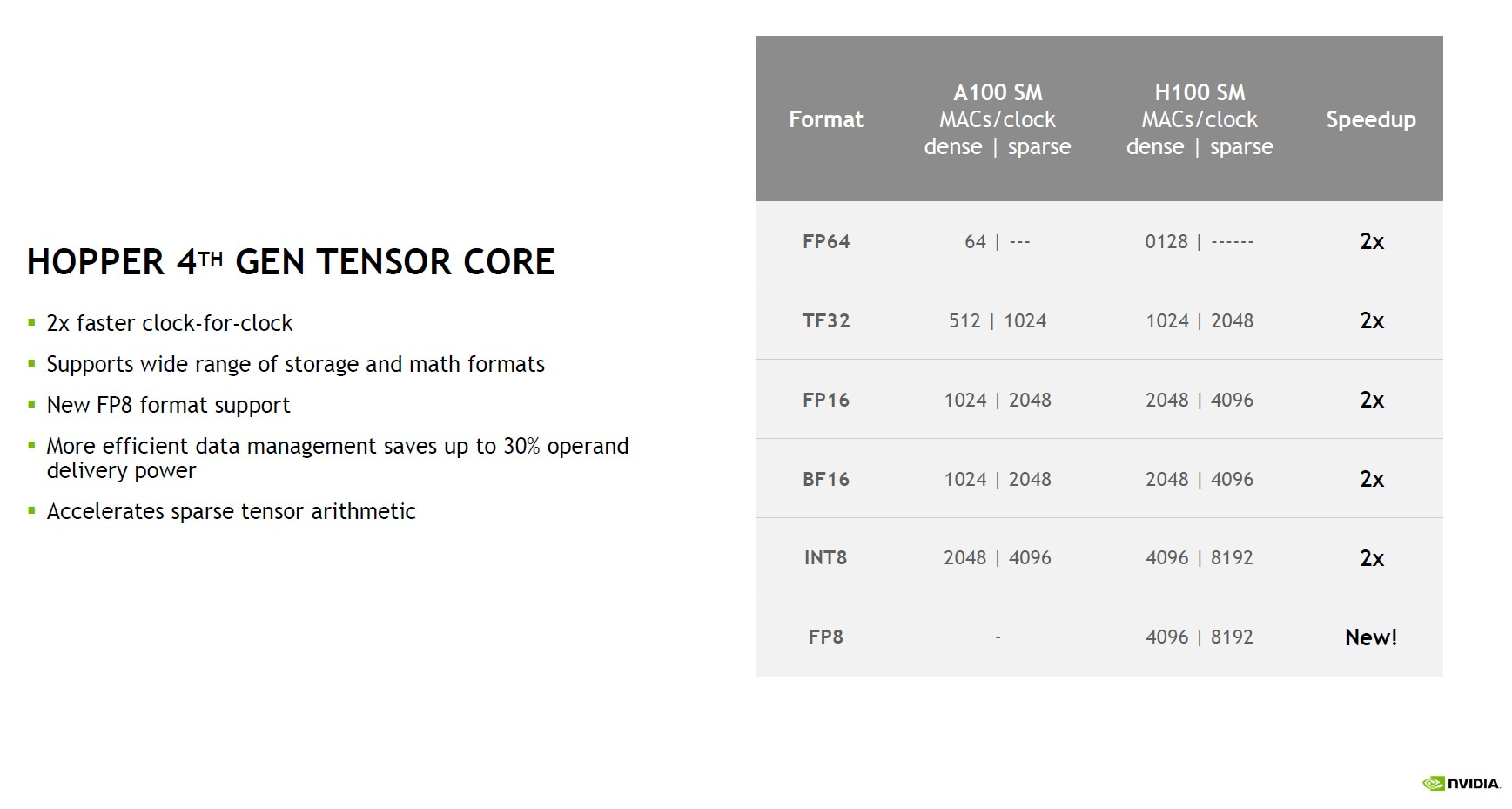 Имеется у GH100 и ещё одно важное нововведение — модифицированная иерархия памяти. Так, интерконнект SM-to-SM позволяет каждым четырём SM общаться между собой напрямую, а не загружать излишними транзакциями общую шину. Это повышает эффективности при виртуализации и серьёзно экономит пропускную способность «главных трактов» ускорителя. Вкупе с поддержкой асинхронного исполнения и обмена данными это позволит снизить латентность, в некоторых случаях до семи раз. 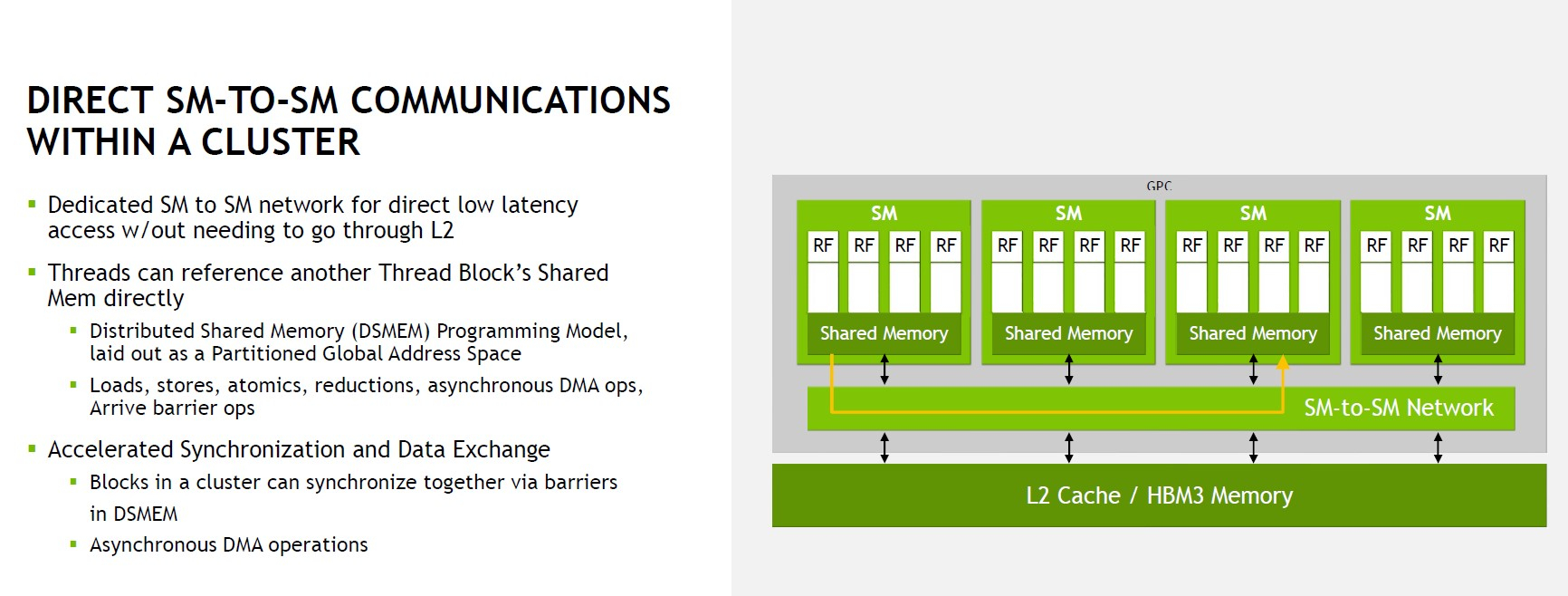 Реализует ли NVIDIA потенциал GH100 полностью, на данный момент неясно, но это могло бы повысить и без того серьёзный потенциал новинки. Впрочем, такая мощь даром не даётся: даже в усечённой версии и даже несмотря на использование оптимизированного техпроцесса ускоритель на базе GH100 в формате SXM5 (плата PG520) будет иметь теплопакет 700 Вт.  Несомненно, GH100 —огромный шаг вперёд в сравнении с GA100, однако конкуренция предстоит серьёзная: так, новинке предстоит сразиться с ускорителями на базe Intel Ponte Vecchio, а в них обещается соотношение FP32/FP64 на уровне 1:1 против 2:1 у решения NVIDIA. Любопытный факт: единственный кластер GPC у нового чипа на 20% мощнее всего чипа GK110 Kepler, выпущенного всего 10 лет назад.
25.08.2022 [15:06], Алексей Разин
Поставки ускорителей NVIDIA Hopper достигнут значимых величин только в IV кварталеВо II квартале, как стало известно ранее, именно серверный сегмент стал локомотивом роста выручки NVIDIA на 3 % в годовом сравнении, тогда как в игровом сегменте наблюдалось её резкое снижение. В III квартале руководство компании рассчитывает на рост выручки в серверном сегменте, но основной объём поставок ускорителей Hopper придётся на IV квартал, поэтому он может оказаться лучше III квартала в плане финансовой статистики. Скромный прогноз по выручке на III квартал стал основной причиной снижения курса акций NVIDIA после публикации финансового отчёта. В III квартале выручка от игровых и профессиональных видеокарт продолжат снижаться, а серверное направление и автомобильные компоненты не смогут компенсировать это влияние ростом своей выручки. В итоге в III квартале NVIDIA сможет выручить не более $5,9 млрд против $6,7 млрд во II квартале. 
Источник изображения: NVIDIA Генеральный директор компании Дженсен Хуанг (Jensen Huang) добавил, что ускорители Hopper сейчас выпускают серийно, на подходе и семейство Hopper 2, которым уже интересуются провайдеры облачных услуг. В значимых количествах поставки ускорителей Hopper будут развёрнуты в IV квартале. Что характерно, подобные заявления руководства компании совпали с прогнозами аналитиков Citi, которые накануне предположили, что задержка с поставками процессоров Intel Xeon Sapphire Rapids отсрочат момент экспансии поставок Hopper до IV квартала. По мнению экспертов, в III квартале рост выручки NVIDIA в серверном сегменте будет не 6 %, которые упоминаются в прогнозах других источников, а меньше. Зато в IV квартале начало активных поставок Hopper окажет поддержку NVIDIA. По мнению представителей Citi, наращивание поставок ускорителей поколения Hopper в целом осуществляется в соответствии с ожиданиями рынка. Специалисты Mizuho Securities заявили, что серверные доходы NVIDIA в краткосрочной перспективе способны так или иначе компенсировать слабость игрового сегмента, а в сегменте ускорителей для систем машинного обучения и сопутствующего ПО доля компании вообще превышает 95 %, что само по себе гарантирует определённую стабильность будущего. Эксперты KeyBanc Capital отметили, что ситуация со складскими запасами NVIDIA в серверном сегменте начинает отображать снижение интереса к продуктам поколения Ampere и появление высоких ожиданий, связанных с продуктами поколения Hopper. Основатель NVIDIA считает семейство ускорителей Hopper 2 «трамплином для будущего роста». Из пояснений финансового директора Колетт Кресс (Colette Kress) стало известно, что во II квартале рост выручки в серверном сегменте сдерживался дефицитом сопутствующих компонентов, да и клиенты в сложных макроэкономических условиях стали если не урезать бюджеты, то хотя бы растягивать выплаты во времени. Особенно это чувствовалось в Китае, где экономика была подорвана затяжными локдаунами. Во II квартале NVIDIA учла выручку в размере $287 млн по тем серверным заказам, которые фактически уже были отгружены, но будут оплачены только в III квартале. При этом часть заказов пришлось перенести на III квартал из-за перебоев в поставках.
22.03.2022 [18:40], Игорь Осколков
NVIDIA анонсировала 4-нм ускорители Hopper H100 и самый быстрый в мире ИИ-суперкомпьютер EOS на базе DGX H100На GTC 2022 компания NVIDIA анонсировала ускорители H100 на базе новой архитектуры Hopper. Однако NVIDIA уже давно говорит о себе как создателе платформ, а не отдельных устройств, так что вместе с H100 были представлены серверные Arm-процессоры Grace, в том числе гибридные, а также сетевые решения и обновления наборов ПО. 
NVIDIA H100 (Изображения: NVIDIA) NVIDIA H100 использует мультичиповую 2.5D-компоновку CoWoS и содержит порядка 80 млрд транзисторов. Но нет, это не самый крупный чип компании на сегодняшний день. Кристаллы новинки изготавливаются по техпроцессу TSMC N4, а сопровождают их — впервые в мире, по словам NVIDIA — сборки памяти HBM3 суммарным объёмом 80 Гбайт. Объём памяти по сравнению с A100 не вырос, зато в полтора раза увеличилась её скорость — до рекордных 3 Тбайт/с. 
NVIDIA H100 (SXM) Подробности об архитектуре Hopper будут представлены чуть позже. Пока что NVIDIA поделилась некоторыми сведениями об особенностях новых чипов. Помимо прироста производительности от трёх (для FP64/FP16/TF32) до шести (FP8) раз в сравнении с A100 в Hopper появилась поддержка формата FP8 и движок Transformer Engine. Именно они важны для достижения высокой производительности, поскольку само по себе четвёртое поколение ядер Tensor Core стало втрое быстрее предыдущего (на всех форматах). 
NVIDIA H100 CNX (PCIe) TF32 останется форматом по умолчанию при работе с TensorFlow и PyTorch, но для ускорения тренировки ИИ-моделей NVIDIA предлагает использовать смешанные FP8/FP16-вычисления, с которыми Tensor-ядра справляются эффективно. Хитрость в том, что Transformer Engine на основе эвристик позволяет динамически переключаться между ними при работе, например, с каждым отдельным слоем сети, позволяя таким образом добиться повышения скорости обучения без ущерба для итогового качества модели. На больших моделях, а именно для таких H100 и создавалась, сочетание Transformer Engine с другими особенностями ускорителей (память и интерконнект) позволяет получить девятикратный прирост в скорости обучения по сравнению с A100. Но Transformer Engine может быть полезен и для инференса — готовые FP8-модели не придётся самостоятельно конвертировать в INT8, движок это сделает на лету, что позволяет повысить пропускную способность от 16 до 30 раз (в зависимости от желаемого уровня задержки). 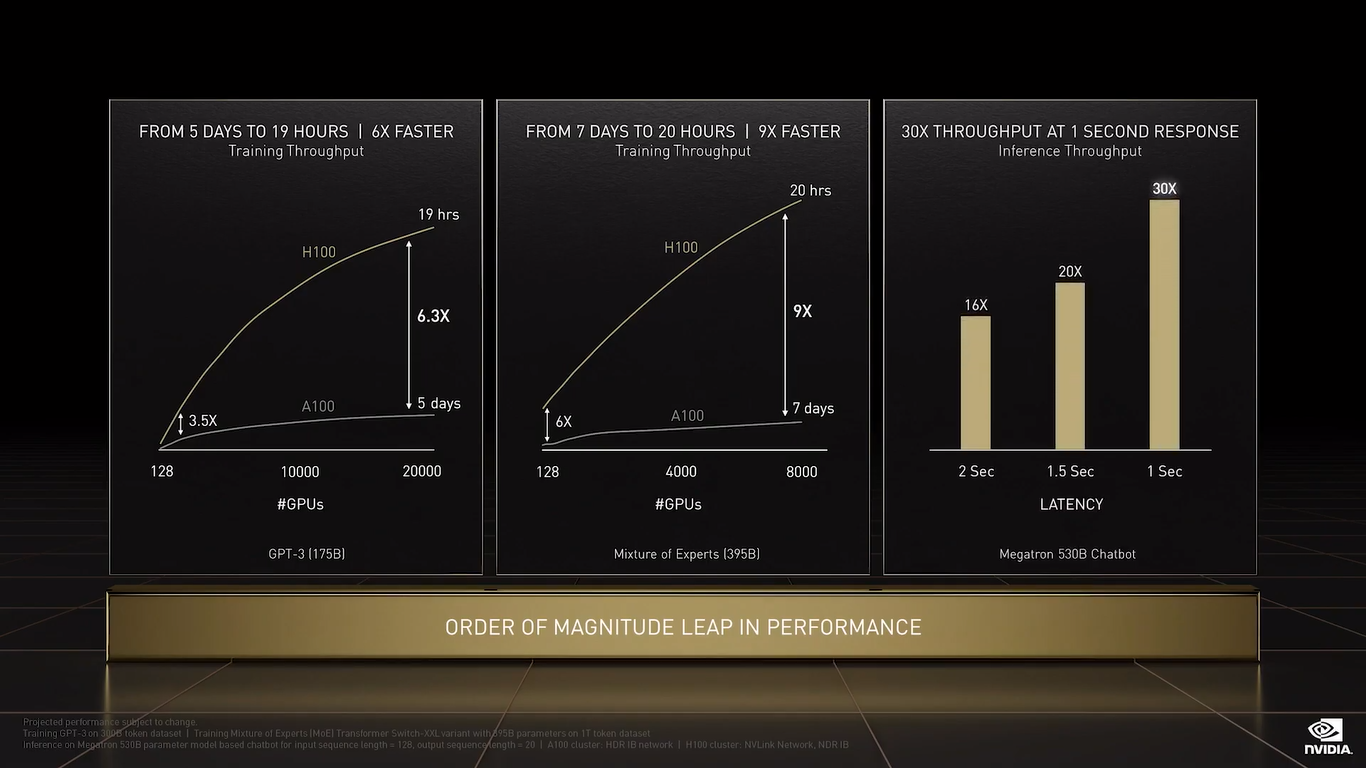 Другое любопытное нововведение — специальные DPX-инструкции для динамического программирования, которые позволят ускорить выполнение некоторых алгоритмов до 40 раз в задачах, связанных с поиском пути, геномикой, квантовыми системами и при работе с большими объёмами данных. Кроме того, H100 получили дальнейшее развитие виртуализации. В новых ускорителях всё так же поддерживается MIG на 7 инстансов, но уже второго поколения, которое привнесло больший уровень изоляции благодаря IO-виртуализации, выделенным видеоблокам и т.д.  Так что MIG становится ещё более предпочтительным вариантом для облачных развёртываний. Непосредственно к MIG примыкает и технология конфиденциальных вычислений, которая по словам компании впервые стала доступна не только на CPU. Программно-аппаратное решение позволяет создавать изолированные ВМ, к которым нет доступа у ОС, гипервизора и других ВМ. Поддерживается сквозное шифрование при передаче данных от CPU к ускорителю и обратно, а также между ускорителями.  Память внутри GPU также может быть изолирована, а сам ускоритель оснащается неким аппаратным брандмауэром, который отслеживает трафик на шинах и блокирует несанкционированный доступ даже при наличии у злоумышленника физического доступа к машине. Это опять-таки позволит без опаски использовать H100 в облаке или в рамках колокейшн-размещения для обработки чувствительных данных, в том числе для задач федеративного обучения.  NVIDIA HGX H100 Но главная инновация — это существенное развитие интерконнекта по всем фронтам. Суммарная пропускная способность внешних интерфейсов чипа H100 составляет 4,9 Тбайт/с. Да, у H100 появилась поддержка PCIe 5.0, тоже впервые в мире, как утверждает NVIDIA. Однако ускорители получили не только новую шину NVLink 4.0, которая стала в полтора раза быстрее (900 Гбайт/с), но и совершенно новый коммутатор NVSwitch, который позволяет напрямую объединить между собой до 256 ускорителей! Пропускная способность «умной» фабрики составляет до 70,4 Тбайт/с.  Сама NVIDIA предлагает как новые системы DGX H100 (8 × H100, 2 × BlueField-3, 8 × ConnectX-7), так и SuperPOD-сборку из 32-х DGX, как раз с использованием NVLink и NVSwitch. Партнёры предложат HGX-платформы на 4 или 8 ускорителей. Для дальнейшего масштабирования SuperPOD и связи с внешним миром используются 400G-коммутаторы Quantum-2 (InfiniBand NDR). Сейчас NVIDIA занимается созданием своего следующего суперкомпьютера EOS, который будет состоять из 576 DGX H100 и получит FP64-производительность на уровне 275 Пфлопс, а FP16 — 9 Эфлопс.  Компания надеется, что EOS станет самой быстрой ИИ-машиной в мире. Появится она чуть позже, как и сами ускорители, выход которых запланирован на III квартал 2022 года. NVIDIA представит сразу три версии. Две из них стандартные, в форм-факторах SXM4 (700 Вт) и PCIe-карты (350 Вт). А вот третья — это конвергентный ускоритель H100 CNX со встроенными DPU Connect-X7 класса 400G (подключение PCIe 5.0 к самому ускорителю) и интерфейсом PCIe 4.0 для хоста. Компанию ей составят 400G/800G-коммутаторы Spectrum-4. |
|

