Материалы по тегу: hgx
|
19.05.2022 [17:57], Сергей Карасёв
Gigabyte представила высокопроизводительный Arm-сервер G492-PD0: Ampere Altra + 8 × NVIDIA A100Gigabyte анонсировала 4U-сервер G492-PD0, предназначенный для облачных платформ, систем ИИ и инфраструктур высокопроизводительных вычислений (HPC). Допускается установка одного процессора Ampere Altra (Max), насчитывающего до 128 ядер. Есть 16 слотов для модулей оперативной памяти DDR4-3200 ёмкостью до 256 Гбайт каждый. А главное — поддержка до восьми 80-Гбайт ускорителей NVIDIA A100 в составе HGX-платы Delta. 
Изображение: Gigabyte Technology Предусмотрены шесть посадочных мест для SFF-накопителей NVMe/SATA. Кроме того, могут быть задействованы четыре модуля M.2 формата 2260/2280/22110. Для всех накопителей предусмотрена поддержка PCIe 4.0, равно как и для десяти PCIe-слотов для низкопрофильных карт расширения. В оснащение входят двухпортовый сетевой контроллер 1GbE и выделенный 1GbE-порт управления для BMC ASPEED AST2500. 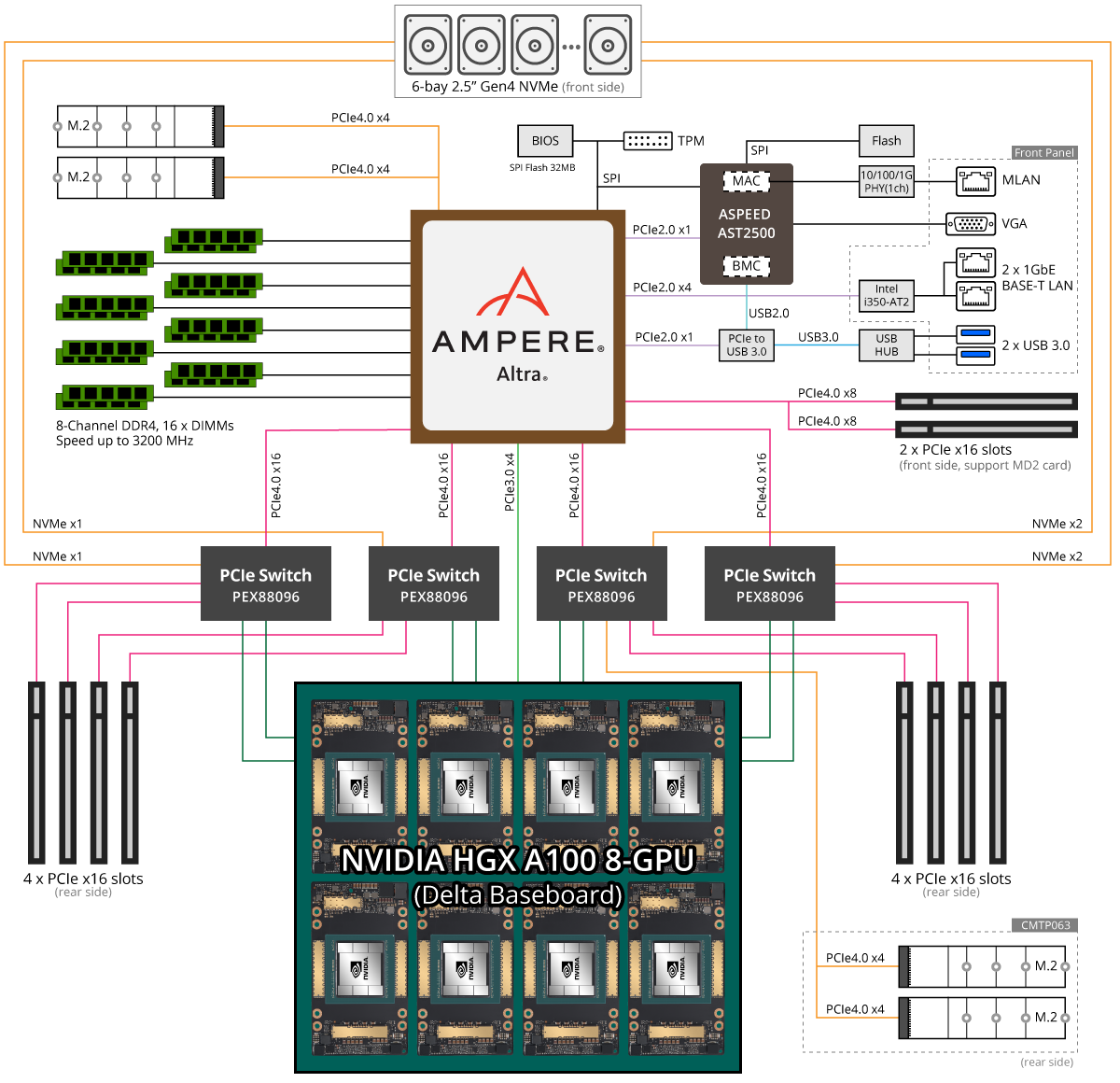
Изображение: Gigabyte Technology Габариты сервера составляют 448 × 175,2 × 900 мм. Применена система воздушного охлаждения, включающая одиннадцать 80-мм вентиляторов и десять — 40-мм. Питается сервер от четырёх (3+1) БП мощностью 3 кВт каждый. Говорится о совместимости с программной платформой Ubuntu 20.04.1 LTS (ядро 5.8 или новее) и соответствии стандартам Arm SystemReady и Arm ServerReady.
22.03.2022 [18:40], Игорь Осколков
NVIDIA анонсировала 4-нм ускорители Hopper H100 и самый быстрый в мире ИИ-суперкомпьютер EOS на базе DGX H100На GTC 2022 компания NVIDIA анонсировала ускорители H100 на базе новой архитектуры Hopper. Однако NVIDIA уже давно говорит о себе как создателе платформ, а не отдельных устройств, так что вместе с H100 были представлены серверные Arm-процессоры Grace, в том числе гибридные, а также сетевые решения и обновления наборов ПО. 
NVIDIA H100 (Изображения: NVIDIA) NVIDIA H100 использует мультичиповую 2.5D-компоновку CoWoS и содержит порядка 80 млрд транзисторов. Но нет, это не самый крупный чип компании на сегодняшний день. Кристаллы новинки изготавливаются по техпроцессу TSMC N4, а сопровождают их — впервые в мире, по словам NVIDIA — сборки памяти HBM3 суммарным объёмом 80 Гбайт. Объём памяти по сравнению с A100 не вырос, зато в полтора раза увеличилась её скорость — до рекордных 3 Тбайт/с. 
NVIDIA H100 (SXM) Подробности об архитектуре Hopper будут представлены чуть позже. Пока что NVIDIA поделилась некоторыми сведениями об особенностях новых чипов. Помимо прироста производительности от трёх (для FP64/FP16/TF32) до шести (FP8) раз в сравнении с A100 в Hopper появилась поддержка формата FP8 и движок Transformer Engine. Именно они важны для достижения высокой производительности, поскольку само по себе четвёртое поколение ядер Tensor Core стало втрое быстрее предыдущего (на всех форматах). 
NVIDIA H100 CNX (PCIe) TF32 останется форматом по умолчанию при работе с TensorFlow и PyTorch, но для ускорения тренировки ИИ-моделей NVIDIA предлагает использовать смешанные FP8/FP16-вычисления, с которыми Tensor-ядра справляются эффективно. Хитрость в том, что Transformer Engine на основе эвристик позволяет динамически переключаться между ними при работе, например, с каждым отдельным слоем сети, позволяя таким образом добиться повышения скорости обучения без ущерба для итогового качества модели. На больших моделях, а именно для таких H100 и создавалась, сочетание Transformer Engine с другими особенностями ускорителей (память и интерконнект) позволяет получить девятикратный прирост в скорости обучения по сравнению с A100. Но Transformer Engine может быть полезен и для инференса — готовые FP8-модели не придётся самостоятельно конвертировать в INT8, движок это сделает на лету, что позволяет повысить пропускную способность от 16 до 30 раз (в зависимости от желаемого уровня задержки). 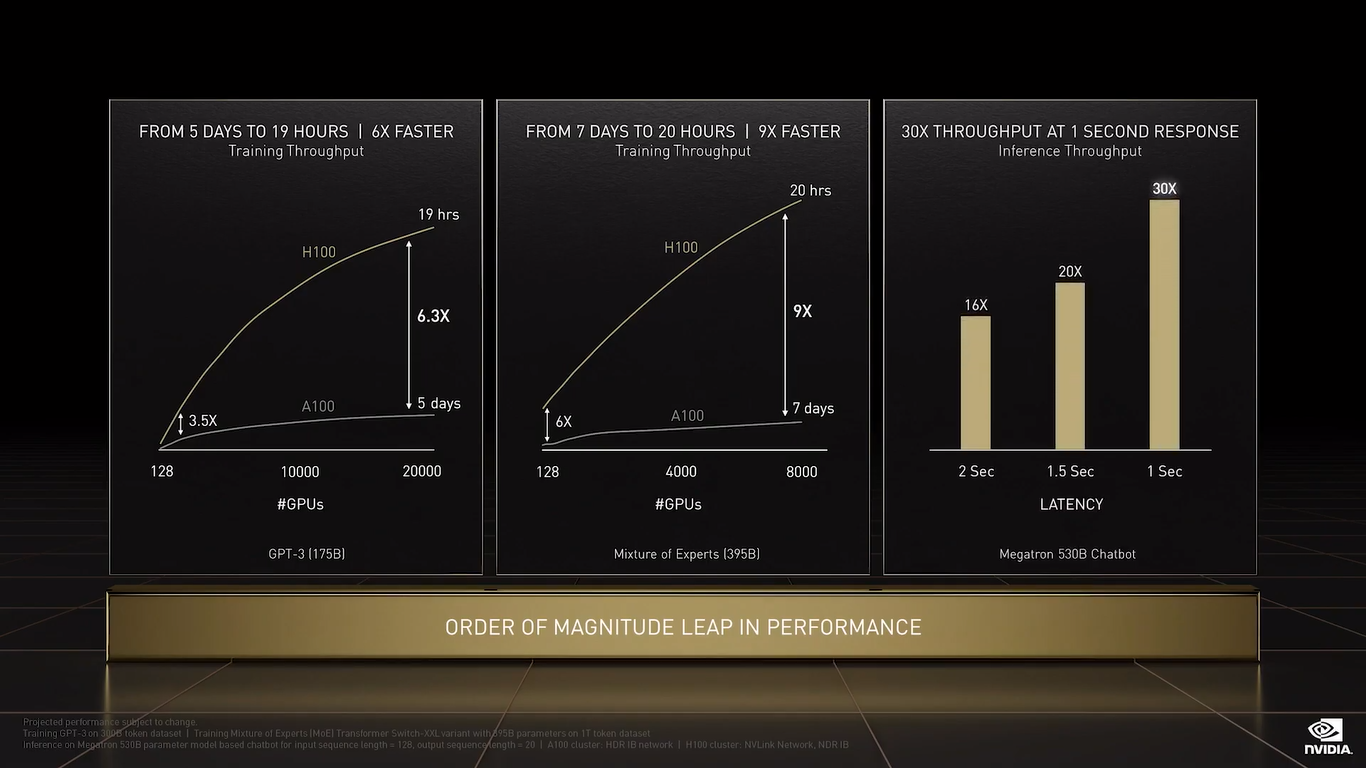 Другое любопытное нововведение — специальные DPX-инструкции для динамического программирования, которые позволят ускорить выполнение некоторых алгоритмов до 40 раз в задачах, связанных с поиском пути, геномикой, квантовыми системами и при работе с большими объёмами данных. Кроме того, H100 получили дальнейшее развитие виртуализации. В новых ускорителях всё так же поддерживается MIG на 7 инстансов, но уже второго поколения, которое привнесло больший уровень изоляции благодаря IO-виртуализации, выделенным видеоблокам и т.д.  Так что MIG становится ещё более предпочтительным вариантом для облачных развёртываний. Непосредственно к MIG примыкает и технология конфиденциальных вычислений, которая по словам компании впервые стала доступна не только на CPU. Программно-аппаратное решение позволяет создавать изолированные ВМ, к которым нет доступа у ОС, гипервизора и других ВМ. Поддерживается сквозное шифрование при передаче данных от CPU к ускорителю и обратно, а также между ускорителями.  Память внутри GPU также может быть изолирована, а сам ускоритель оснащается неким аппаратным брандмауэром, который отслеживает трафик на шинах и блокирует несанкционированный доступ даже при наличии у злоумышленника физического доступа к машине. Это опять-таки позволит без опаски использовать H100 в облаке или в рамках колокейшн-размещения для обработки чувствительных данных, в том числе для задач федеративного обучения.  NVIDIA HGX H100 Но главная инновация — это существенное развитие интерконнекта по всем фронтам. Суммарная пропускная способность внешних интерфейсов чипа H100 составляет 4,9 Тбайт/с. Да, у H100 появилась поддержка PCIe 5.0, тоже впервые в мире, как утверждает NVIDIA. Однако ускорители получили не только новую шину NVLink 4.0, которая стала в полтора раза быстрее (900 Гбайт/с), но и совершенно новый коммутатор NVSwitch, который позволяет напрямую объединить между собой до 256 ускорителей! Пропускная способность «умной» фабрики составляет до 70,4 Тбайт/с.  Сама NVIDIA предлагает как новые системы DGX H100 (8 × H100, 2 × BlueField-3, 8 × ConnectX-7), так и SuperPOD-сборку из 32-х DGX, как раз с использованием NVLink и NVSwitch. Партнёры предложат HGX-платформы на 4 или 8 ускорителей. Для дальнейшего масштабирования SuperPOD и связи с внешним миром используются 400G-коммутаторы Quantum-2 (InfiniBand NDR). Сейчас NVIDIA занимается созданием своего следующего суперкомпьютера EOS, который будет состоять из 576 DGX H100 и получит FP64-производительность на уровне 275 Пфлопс, а FP16 — 9 Эфлопс.  Компания надеется, что EOS станет самой быстрой ИИ-машиной в мире. Появится она чуть позже, как и сами ускорители, выход которых запланирован на III квартал 2022 года. NVIDIA представит сразу три версии. Две из них стандартные, в форм-факторах SXM4 (700 Вт) и PCIe-карты (350 Вт). А вот третья — это конвергентный ускоритель H100 CNX со встроенными DPU Connect-X7 класса 400G (подключение PCIe 5.0 к самому ускорителю) и интерфейсом PCIe 4.0 для хоста. Компанию ей составят 400G/800G-коммутаторы Spectrum-4.
28.06.2021 [13:22], Алексей Степин
Обновление NVIDIA HGX: PCIe-вариант A100 с 80 Гбайт HBM2e, InfiniBand NDR и Magnum IO с GPUDirect StorageНа суперкомпьютерной выставке-конференции ISC 2021 компания NVIDIA представила обновление платформы HGX A100 для OEM-поставщиков, которая теперь включает PCIe-ускорители NVIDIA c 80 Гбайт памяти, InfiniBand NDR и поддержку Magnum IO с GPUDirect Storage. В основе новинки лежат наиболее продвинутые на сегодняшний день технологии, имеющиеся в распоряжении NVIDIA. В первую очередь, это, конечно, ускорители на базе архитектуры Ampere, оснащённые процессорами A100 с производительностью почти 10 Тфлопс в режиме FP64 и 624 Топс в режиме тензорных вычислений INT8.  HGX A100 предлагает 300-Вт версию ускорителей с PCIe 4.0 x16 и удвоенным объёмом памяти HBM2e (80 Гбайт). Увеличена и пропускная способность (ПСП), в новой версии ускорителя она достигла 2 Тбайт/с. И если по объёму и ПСП новинки догнали SXM-версию A100, то в отношении интерконнекта они всё равно отстают, так как позволяют напрямую объединить посредством NVLink только два ускорителя.  В качестве сетевой среды в новой платформе NVIDIA применена технология InfiniBand NDR со скоростью 400 Гбит/с. Можно сказать, что InfiniBand догнала Ethernet, хотя не столь давно её потолком были 200 Гбит/с, а в плане латентности IB по-прежнему нет равных. Сетевые коммутаторы NVIDIA Quantum 2 поддерживают до 64 портов InfiniBand NDR и вдвое больше для скорости 200 Гбит/с, а также имеют модульную архитектуру, позволяющую при необходимости нарастить количество портов NDR до 2048. Пропускная способность при этом может достигать 1,64 Пбит/с.  Технология NVIDIA SHARP In-Network Computing позволяет компании заявлять о 32-крантом превосходстве над системами предыдущего поколения именно в области сложных задач машинного интеллекта для индустрии и науки. Естественно, все преимущества машинной аналитики используются и внутри самого продукта — технология UFM Cyber-AI позволяет новой платформе исправлять большинство проблем с сетью на лету, что минимизирует время простоя.  Отличным дополнением к новым сетевым возможностями является технология GPUDirect Storage, которая позволяет NVMe-накопителям общаться напрямую с GPU, минуя остальные компоненты системы. В качестве программной прослойки для обслуживания СХД новая платформа получила систему Magnum IO с поддержкой вышеупомянутой технологии, обладающую низкой задержкой ввода-вывода и по максимуму способной использовать InfiniBand NDR. 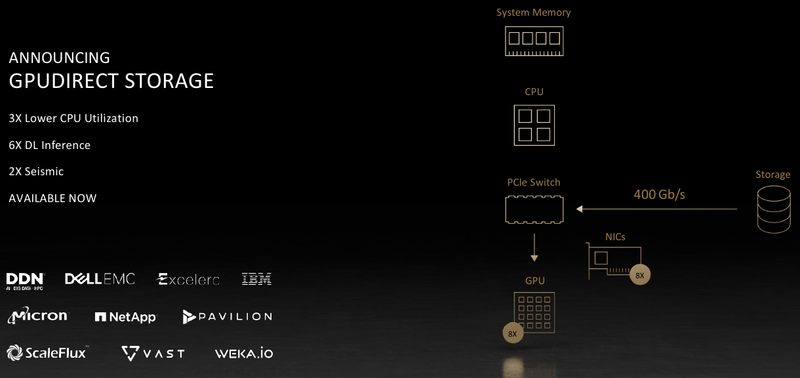 Три новых ключевых технологии NVIDIA помогут супервычислениям стать ещё более «супер», а суперкомпьютерам следующего поколения — ещё более «умными» и производительными. Достигнуты договорённости с такими крупными компаниями, как Atos, Dell Technologies, HPE, Lenovo, Microsoft Azure и NetApp. Решения NVIDIA используются как в индустрии — в качестве примера можно привести промышленный суперкомпьютер Tesla Automotive, так и в ряде других областей.  В частности, фармакологическая компания Recursion использует наработки NVIDIA в области машинного обучения для поиска новых лекарств, а национальный научно-исследовательский центр энергетики (NERSC) применяет ускорители A100 в суперкомпьютере Perlmutter при разработке новых источников энергии. И в дальнейшем NVIDIA продолжит своё наступление на рынок HPC, благо, она может предложить заказчикам как законченные аппаратные решения, так и облачные сервисы, также использующие новейшие технологии компании. |
|

