Материалы по тегу: fpga
|
05.10.2022 [20:48], Алексей Степин
Intel поделилась планами по выпуску новых FPGA — новое поколение Agilex выйдет в 2023-2024 годахПопулярность программируемых логических интегральных схем (ПЛИС) сегодня определённо находится на подъёме, поскольку FPGA универсальны по своей природе и позволяют легко реализовать практически любую концепцию сопроцессора. Микросхемы такого типа весьма востребованы в сетях 5G и современной робототехнике. Компания Intel некоторое время задерживалась с обновлением своего модельного ряда ПЛИС, опираясь на серию Agilex 2021 года, выпускаемую с использованием техпроцесса 10 нм SuperFin, но теперь она намеревается наверстать упущенное уже в 2023–2024 годах. 
Источник изображений: Intel. Полные версии изображений открываются по нажатию. Новое поколение ПЛИС серии Agilex M запланировано именно на этот период, но основные изменения коснутся технологических процессов — Intel переведёт эти чипы на использование техпроцесса Intel 7, также относящегося к классу «10 нм», но более совершенного. Однако на этот же период запланирован и выпуск ПЛИС Agilex нового поколения. Как отмечает Шэннон Поулин (Shannon Poulin), глава отдела программируемых решений Intel, компания во многом полагается на унаследованные продукты, многие из которых были разработаны не самой Intel, а некоторые насчитывают 5–10–20 лет, поэтому Intel предстоит много работы. 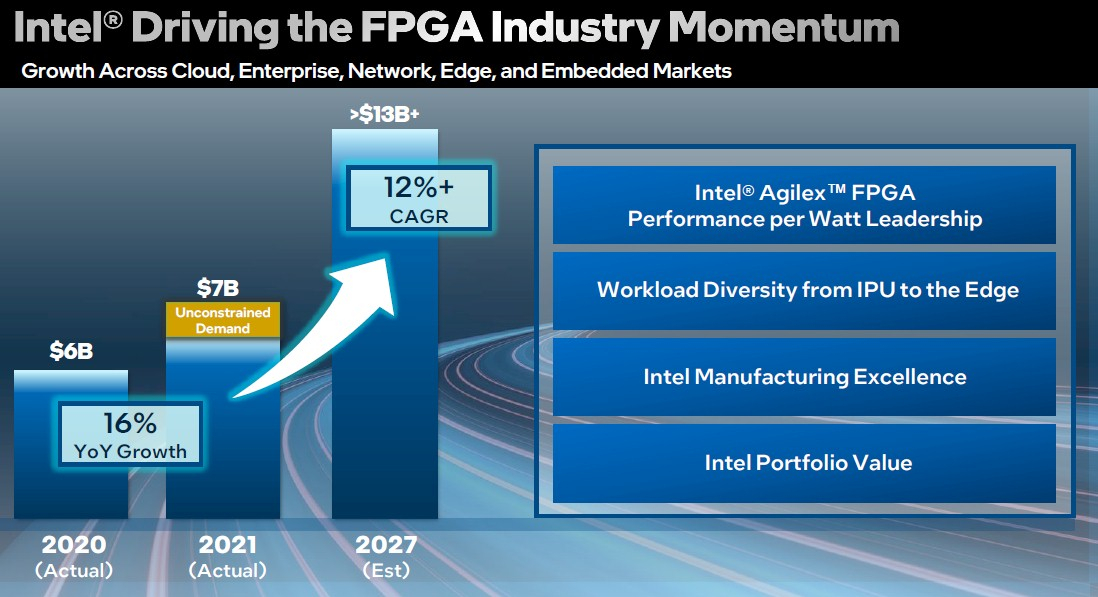 В настоящее время компания активно работает именно над совершенствованием модульных технологий, позволяющих интегрировать ПЛИС-чиплеты с поддержкой интерфейсов UCIe, PCI Express 5.0 и CXL в широкий круг чипов, от ускорителей машинного обучения и GPU до традиционных процессоров с архитектурами x86 и RISC-V. Эта интеграция будет использовать интерфейс AIB (Advanced Interface Bus). Компания активно сотрудничает с крупными производителями электроники, такими как Texas Instruments, и уже располагает рабочими образцами ПЛИС-чиплетов нового поколения. 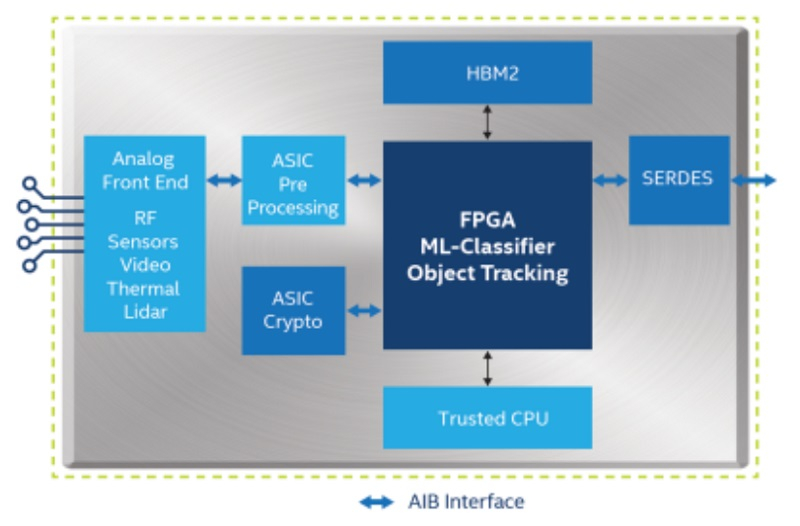 Также Intel планирует наверстать отставание в секторе ПЛИС среднего класса с новой серией чипов Agilex D. Эта новинка получит 100 тыс. элементов, поддержку экономичной памяти DDR5 и новый интерконнект «smart fabric». Первые серии Agilex D увидят свет в 2023 году с дальнейшими массовыми поставками в 2024.  Новое семейство Agilex под кодовым названием Sundance Mesa будет представлять собой примерно половину Agilex D с приблизительно 50 тыс. элементов. Эта новинка нацелена на рынок потребительских решений в области машинного интеллекта.  Несмотря на активное продвижение модульного подхода к конструированию ПЛИС, последние две новинки в сериях Agilex D и Sundance Mesa будут использовать традиционный монолитный дизайн кристалла, но именно они помогут Intel укрепить позиции на рынке ПЛИС малого и среднего классов. Однако компании придется активно состязаться с AMD, располагающей активами Xilinx и активно завоёвывающей с их помощью рынки ЦОД и HPC.
01.09.2022 [16:05], Игорь Осколков
Intel Pathfinder упростит и ускорит разработку RISC-V чиповКорпорация Intel совместно с целым рядом компаний анонсировали новое решение Pathfinder, направленное на помощь в разработке SoC на базе RISC-V. Для Intel Pathfinder for RISC-V вендоры предоставляют ядра RISC-V, IP-блоки и программные решения, которые можно развернуть на FPGA для разработки и отладки, причём работа с такими комплексными прототипами будущих SoC доступна в унифицированной IDE. 
Изображение: Terasic Будет доступно две версии продукта, Starter Edition и Professional Edition. Первая является бесплатной и предназначена для энтузиастов, научных и академических кругов. Она не требует обязательного наличия FPGA, так как позволяет обойтись программным эмулятором. Вторая же ориентирована на разработчиков коммерческих программных и аппаратных решений и получит более широкий набор IP-блоков и ПО. 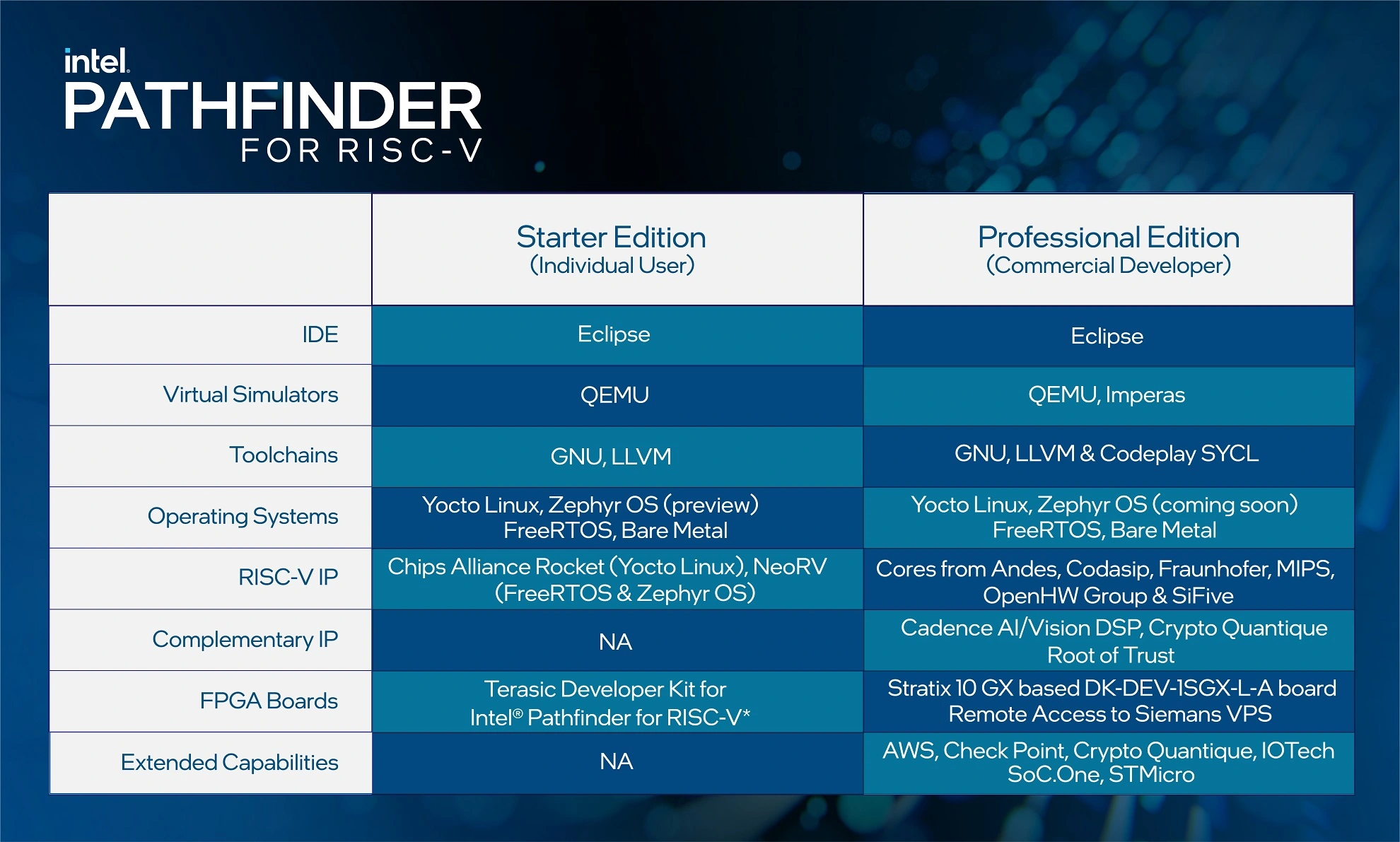
Изображение: Intel (via Embedded.com) К инициативе Pathfinder присоединились два десятка компаний. Andes предоставила процессорные блоки AX45MP и NX27V, от Chips Alliance получены Rocket-ядра, Codasip поделилась ядром L31, Fraunhofer IMS предложила SoC AIRISC, MIPS дала EvoCore P8700 и I8500, OpenHW Group — CVE4 и CVA6, а SiFive — P550. Средства разработки и отладки, а также прочие программные решения предоставили Cadence, Codeplay, Check Point Software Technologies, Imperas, IOTech и Siemens. 
Изображение: Terasic Часть IP-блоков будет получена от STMicroelectronics. Наконец, готовую и недорогую платформу подготовила компания Terasic, её Developer Kit for Intel Pathfinder for RISC-V обойдётся в $449. Плата включает небольшую FPGA Cyclone IV EP4CE115, 128 Мбайт SDRAM, двухстрочный LCD-экран, пару 1GbE-портов и массу стандартных интерфейсов. Ранее, напомним, Intel заявила о желании развивать экосистему RISC-V, а также заключила партнёрские соглашения с Esperanto и Ventana.
04.08.2022 [21:43], Алексей Степин
BittWare анонсировала первые ускорители с интерфейсом CXL на базе FPGA Intel AgilexПроизводители аппаратного обеспечения в последнее время особенно активно анонсируют продукты, разработанные для экосистемы CXL. Пока это, в основном, модули памяти, накопители или контроллеры для самого интерконнекта CXL, но компания BittWare, дочернее предприятие Molex, представила нечто иное — по ряду параметров первые в своём роде ускорители с поддержкой CXL, пусть пока и опциональной. Объединяет серию новинок то, что построены они на базе FPGA Intel Agilex. Всего представлено три новых модели: IA-860m, IA-640i и IA-440i. Возглавляет семейство ускоритель IA-860m, использующий самую мощную ПЛИС Agilex AGM 039, оснащённую собственным банком памяти HBM2e объёмом 16 Гбайт, но версия с поддержкой CXL может комплектоваться уже 32 Гбайт такой памяти. Помимо этого, ускоритель имеет два канала DDR5 для DIMM-модулей и три QSFP-DD (до 400GbE). 
Источник: BittWare Эта модель предназначена для сценариев, требующих высокой пропускной способности одновременно от сетевых каналов и подсистемы памяти. Интересной особенностью является наличие внутренних портов расширения MCIO, каждый из которых представляет собой по два корневых комплекса PCIe 4.0 x4. 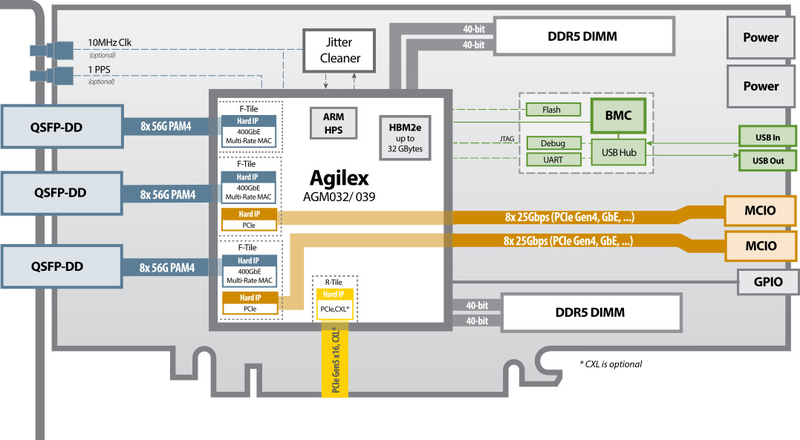
Блок-схема IA-860m. Источник: BittWare Модель IA-640i проще, что видно даже по более скромной однослотовой пассивной системе охлаждения. Здесь устанавливается ПЛИС Intel Agilex AGI 019 или AGI 023, 400GbE-порт QSFP-DD только один, интерфейс MCIO тоже один, памяти HBM нет, а DDR4 заменила DDR5. Поддержка CXL также опциональна, как и в старшей версии, она пока ограничена версией 1.1. Фактически при желании можно просто докупить соответствующий IP-блок. 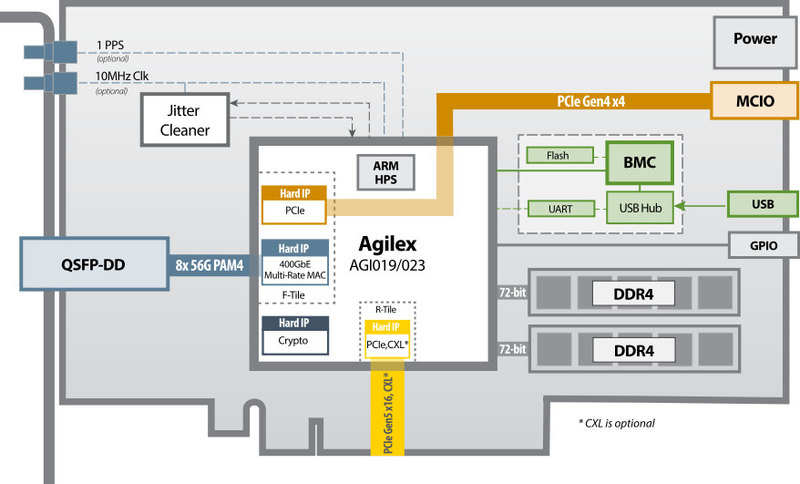
Блок-схема IA-640i. Источник: BittWare Наконец, версия IA-440i предназначена для использования в компактных серверах, она имеет низкопрофильный конструктив, остальные же её характеристики практически аналогичны IA-640i, за исключением того, что из внутренних интерфейсов у этой модели остался только USB. Все ускорители сопровождаются набором фирменного ПО: драйверами, SDK BittWare, библиотеками и утилитами мониторинга. Новинки поддерживают стандарт Intel oneAPI. 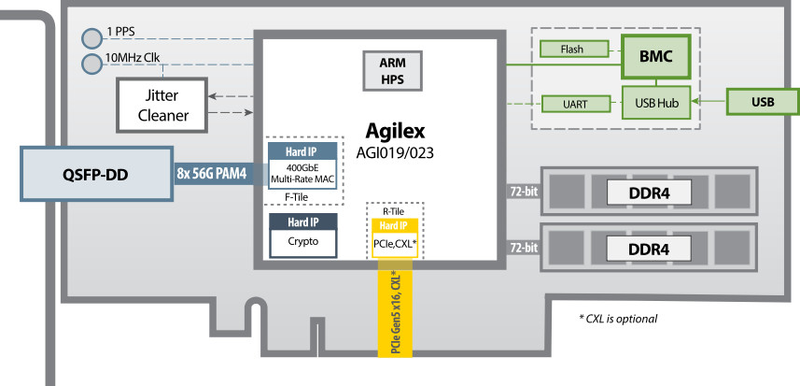
Блок-схема IA-440i. Источник: BittWare Возможности, предоставляемые новыми ускорителями, ограничены только физическими возможностями набортных логических матриц и фантазией разработчиков. Они могут стать основой для инференс-систем, ускорителей работы с базами данных, «вычислительных накопителей», поддержки сетей 5G, обработки потоков данных с массивов различных датчиков в «умной» промышленности и для многого другого. Первые поставки младших моделей запланированы на заключительный квартал этого года с последующим выходом на массовое производство в I квартале 2024 года. А вот первых IA-860m следует ждать не раньше II квартала следующего года, тогда как массовые поставки, согласно опубликованным планам, стартуют лишь годом позже, во II квартале 2024 года.
21.07.2022 [18:16], Алексей Степин
Samsung представила второе поколение «вычислительных» SmartSSD с FPGA Xilinx на бортуИдея «умных» накопителей не нова и довольно очевидна — накопители можно дополнить чипами, которые могут взять на себя первичную обработку данных непосредственно на месте их хранения, например, обслуживая рутинные операции с базами данных или (де-)компрессию на лету и без загрузки CPU хост-системы. Samsung Electronics экспериментирует с данной технологией давно: компания демонстрировала прототипы «вычислительных SSD» ещё на SC18, а в 2020 году уже представила коммерческие накопители SmartSSD, оснащённые мощной ПЛИС Xilinx Kintex, дополненной 4 Гбайт оперативной памяти. Но пришло время двигаться дальше и сегодня компания анонсировала новое поколение накопителей. 
Источник: Samsung Electronics Во втором поколении SmartSSD компания-разработчик сменила FPGA Kintex на более универсальную и производительную платформу Versal. Сама AMD Xilinx называет эти чипы «адаптивной платформой ускорения вычислений», поскольку в них имеются блоки практически на любой случай, от классической ПЛИС до ядер Arm Cortex-A и R, а также DSP и криптодвижки. 
Источник: Samsung Electronics По словам Samsung, новые накопители обрабатывают «тяжёлые» запросы к БД на 50 % быстрее традиционных серверных SSD, при этом они на 70 % экономичнее, а выигрыш по нагрузке на CPU сервера составляет и вовсе 97 %, поскольку основную работу берёт на себя Versal. Главной областью применения SmartSSD нового поколения Samsung видит рынок машинного обучения и сетей пятого и шестого поколений, как требующий активной обработки больших объёмов данных.
18.07.2022 [21:44], Алексей Степин
Arctic Tern от Raptor Computing — полностью открытый BMC на базе FPGABMC можно найти практически в любом сервере или рабочей станции. Этот контроллер отвечает, в числе прочего, и за функции удалённого управления системой. Обычно это чипы Aspeed, хотя крупные производители вроде Dell и HPE используют и собственные решения. Однако всё это закрытые системы, которые могут содержать серьёзные уязвимости и даже специально оставленные бэкдоры. Поэтому компания Raptor Computing Systems решила пойти альтернативным путём. Raptor Computing известна своими решениями на базе IBM POWER с полностью открытым дизайном и программным обеспечением, что нынче редкость. Но эти системы используют проприетарные BMC-чипы, на замену которым компания готовит SoftBMC-решение на базе Kestrel от Raptor Engineering. Kestrel, по словам создателей, является первой в мире действительно открытой реализацией BMC, поскольку доступна и прошивка, и HDL-описание. Работает Kestrel на FPGA. 
Фото: Timothy Pearson / Raptor Engineering Теоретически можно самостоятельно собрать BMC-плату и установить и настроить необходимое ПО, но это довольно трудоёмкий процесс, так что Raptor Computing Systems создала законченное решение под названием Arctic Tern, которое будет совместимо с платформами Blackbird и Talos II. Текущий прототип в формате небольшой PCIe-карты снабжён 1GbE-портом, видеовыходом mini-HDMI и 1 Гбайт DDR3 (SO-DIMM). Одним из преимуществ новинки станет практически мгновенная загрузка после подачи питания, но из-за достаточно медленного открытого OpenPOWER-ядра Microwatt на FPGA разработчики были вынуждены использовать RTOS Zephyr вместо OpenBMC.
10.06.2022 [23:31], Алексей Степин
Решения Xilinx и Pensando помогут AMD завоевать рынок ЦОДО грядущих серверных APU MI300, сочетающих архитектуры Zen 4 и CDNA 3, и сразу нескольких сериях процессоров EPYC мы уже рассказали, но на мероприятии Financial Analyst Day 2022 компания поделилась и другими планами относительно серверного рынка, которые весьма обширны. Они включают в себя использование разработок и технологий Xilinx и Pensando. Фактически AMD теперь владеет полным портфолио аппаратных решений для ЦОД и рынка HPC: процессорами EPYC, ускорителями Instinct, SmartNIC и DPU на базе чипов Xilinx и Pensando и, наконец, FPGA всё той же Xilinx. Долгосрочные перспективы рынка ЦОД AMD оценивает в $125 млрд, из них на долю ускорителей приходится $64 млрд, а классические процессоры занимают лишь второе место с $42 млрд; остальное приходится на DPU, SmartNIC и FPGA. 
Источник: AMD Теперь у AMD есть полный спектр «умных» сетевых решений практически для любой задачи, включая сценарии, требующие сверхнизкой латентности. Эту роль берут на себя адаптеры Solarflare. Более универсальные ускорители Xilix Alveo обеспечат поддержку кастомных сетевых функций и блоков ускорения, а также высокую производительность обработки пакетов. Ускорители могут быть перепрограммированы, что потенциально позволит существенно оптимизировать затраты на сетевую инфраструктуру крупных ЦОД. 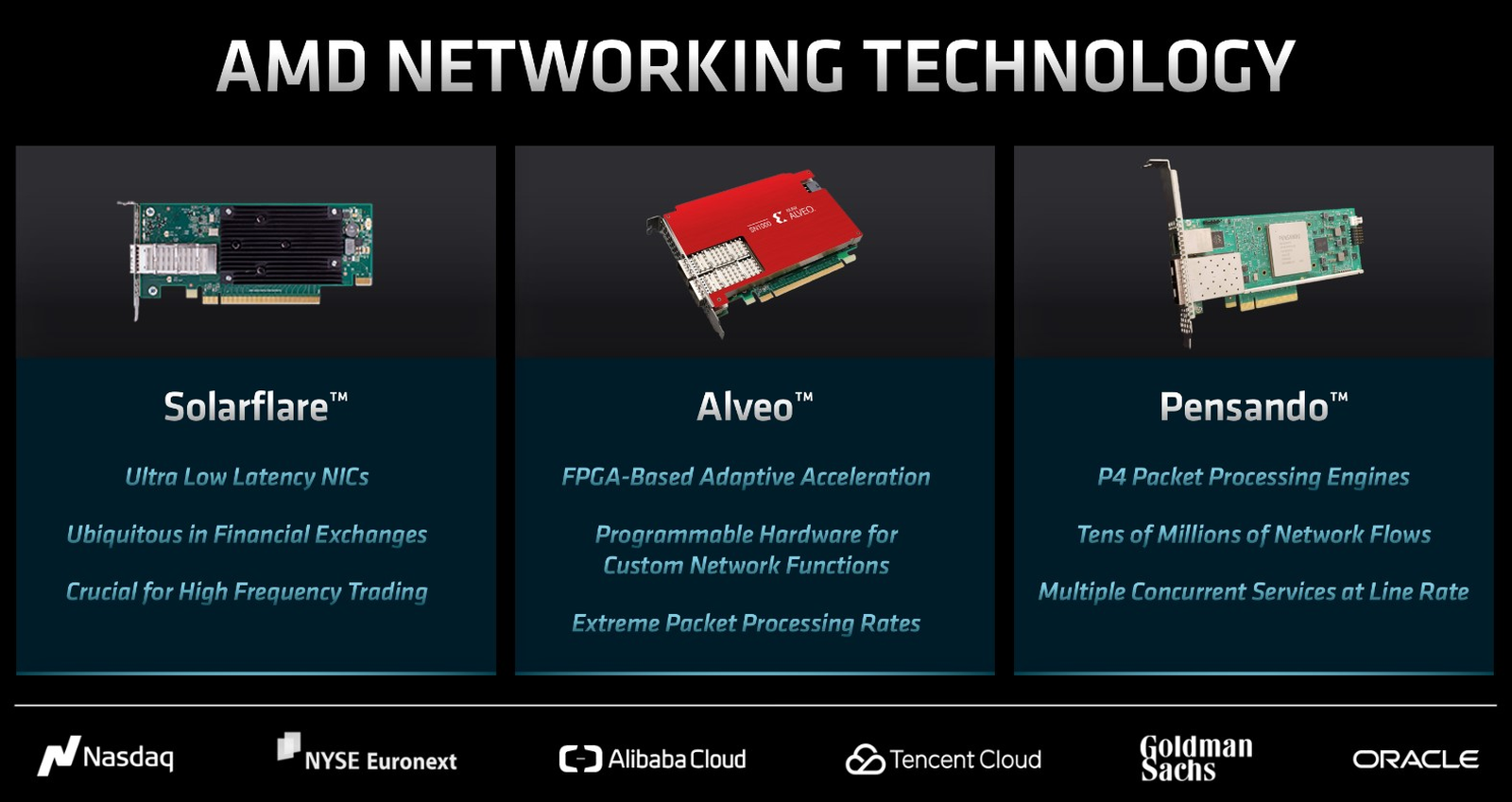
Источник: AMD  Гиперскейлерам они уже поставляются, в текущем виде они имеют до двух 200GbE-портов и совокупную скорость обработки до 400 млн пакетов в секунду. Следующее поколение должно увидеть свет в 2024 году, здесь AMD придерживается двухгодичного цикла. Выпускается и 7-нм DPU Pensando Elba, также предоставляющий пару 200GbE-портов. В отличие от Alveo, это более узкоспециализированное устройство, содержащее 144 P4-программируемых пакетных движка. Помимо них имеются выделенные аппаратные движки ускорения криптографии и сжатия/декомпрессии данных.  Уникальный программно-аппаратный стек Pensando, унаследованный AMD, обеспечивает ряд интересных возможностей, востребованных в крупных системах виртуализации на базе ПО VMware — например, полноценную поддержку виртуализации NVMe, поддержку NVMe-oF/RDMA, в том числе и NVMe/TCP, а также полноценное шифрование и туннели IPSec на полной линейной скорости 100 Гбит/с с временем отклика 3 мкс и джиттером в районе 35 нс. 
Источник: AMD  Разработки Pensando уже используются такими крупными поставщиками сетевого оборудования и СХД, как Aruba (коммутаторы с DPU) и NetApp (системы хранения данных). Таким образом, AMD вполне вправе говорить о том, что современный высокопроизводительный ЦОД может быть целиком построен на базе технологий компании, от процессоров и ускорителей до интерконнекта и специфических акселераторов. 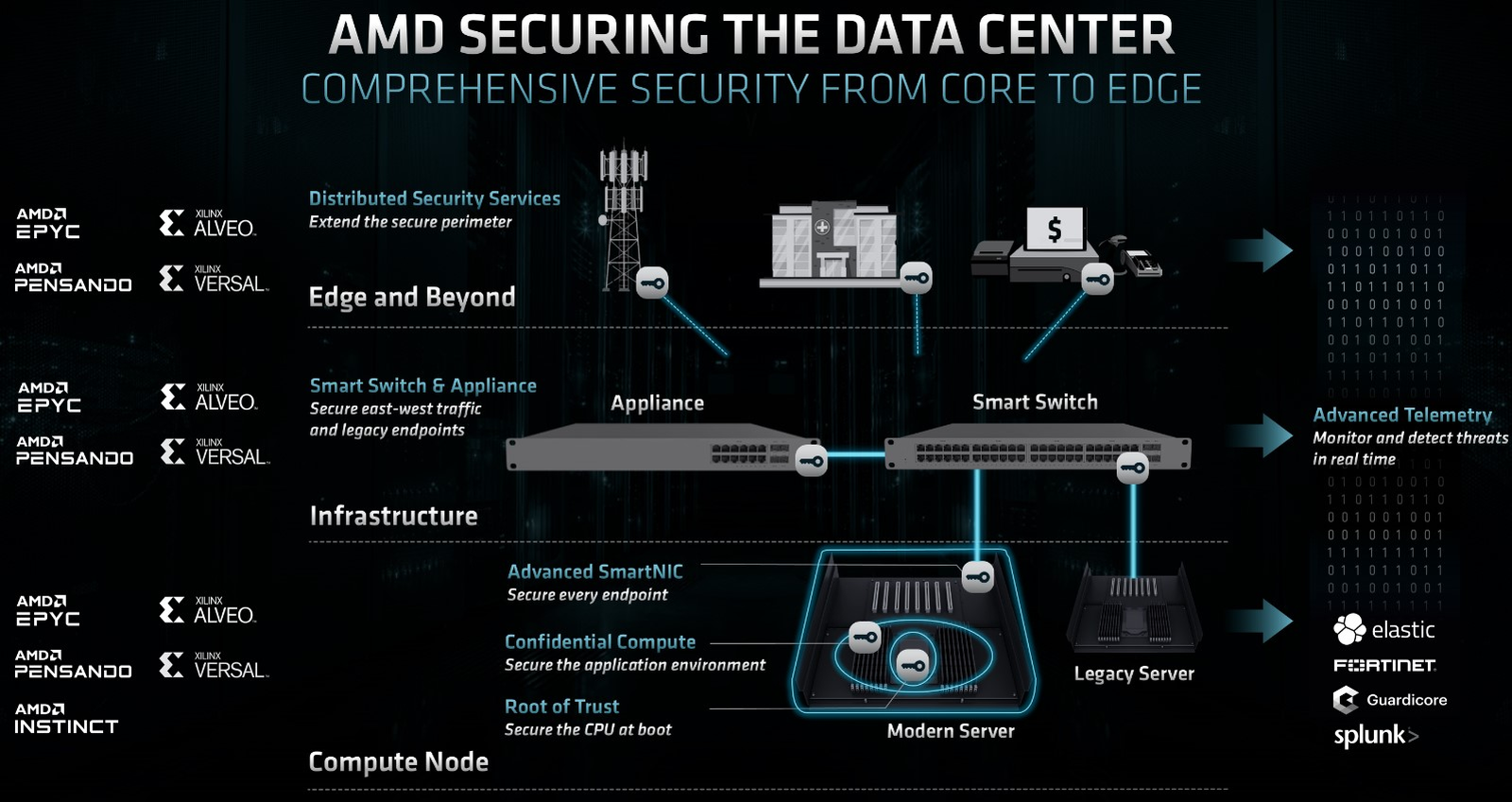
Современный безопасный ЦОД может быть целиком построен на базе технологий AMD. Источник: AMD Поддержка доверенных вычислений, включая полное шифрование содержимого памяти делает такие ЦОД и более безопасными, что немаловажно в современном мире, полном кибер-угроз. В том же направлении движутся NVIDIA BlueField и Intel IPU, а также целый ряд других игроков.
07.06.2022 [21:44], Алексей Степин
Arista Networks анонсировала низколатентные коммутаторы 7130LBR и 7130B на базе решений AMD Xilinx и Intel TofinoСуществуют задачи, в которых главным мерилом производительности сети выступает не пропускная способность, а латентность; к таким, например, относится высокочастотный трейдинг. В погоне за неподатливыми наносекундами компания Arista Networks представила новые низколатентные коммутаторы 7130LBR-48S6QD и 7130B-32QD на базе технологий AMD Xilinx и Intel Tofino. 
Источник: Arista Networks Первая модель очень компактна, она занимает в высоту всего 1U, но при этом располагает 48 портами SFP+ и шестью портами QSFP-DD. Фактически& 7130LBR объединяет в себе низколатентный коммутатор L1+, но к нем подключен как классический кремний Broadcom Jericho 2, так и пара высокопроизводительных ПЛИС Xilinx Virtex UltraScale+ (VU9P-3). За точность отвечает тактовый генератор на базе термостабилизированного модуля OCXO. Джиттер практически отсутствует, а латентность во всех 96 линиях 10G не превышает 6 нс. 
Arista 7130LBR и его архитектура. Источник: Arista Networks Каждая из программируемых матриц имеет по 32 Гбайт памяти DDR4-2400 ECC, что позволяет запускать специализированные приложения, например, MetaMux и MetaWatch (низколатентная агрегация и прецизионные временные отметки). Программное обеспечение хранится на отдельном твердотельном накопителе объёмом 120 Гбайт, при этом, имеется ещё и вспомогательный управляющий x86-процессор Intel, обеспечивающий работу фирменной операционной системы EOS. 
Arista 7130B: детерминированное время отклика 7 нс, платформа Intel Tofino. Источник: Arista Networks Модель 7130B крупнее, она занимает в высоту уже 2U, все 32 10G-порта используют форм-фактор QSFP-DD, а в основе платформы лежит P4-программируемый кремний Intel Tofino. Совокупно этот коммутатор может обслуживать 256 портов с латентностью «хост-хост» в районе 7 нс. При этом 7130B использует конвейер, реализованный в серии 7170, с теми же возможностями, включающими инкапсуляцию, трансляцию адресов и балансировку нагрузки. Благодаря гибкости Tofino, дополнительный маршрутизатор не требуется. Здесь также имеется восьмиядерный процессор x86, отвечающий за работу EOS. 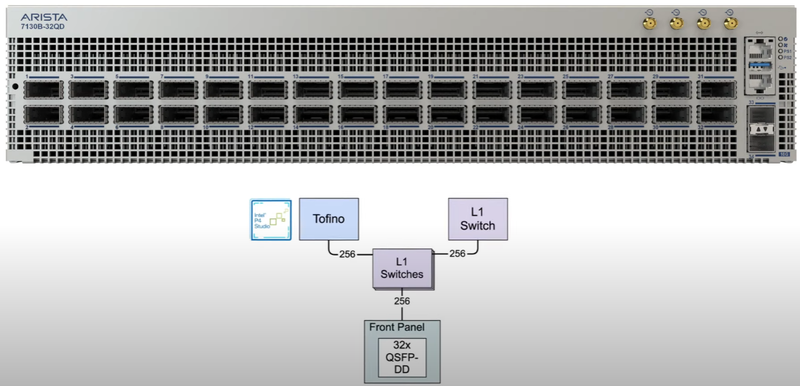
Архитектура Arista 7130B. Источник: Arista Networks В вариантах платформы Arista 7130, оснащённых программируемыми матрицами Xilinx (в зависимости от моделей, от одной до трёх, в 7130LBR их две) обеспечивается наибольшая гибкость и универсальность — поддерживаются программные модули не только самой Arista, но и сторонних разработчиков программного обеспечения; доступна также полная кастомизация. Новинки позволяют одновременно добиться повышения плотности и гибкости L1-инфраструктуры, которую при желании можно дополнить L2/L3-функциями или же реализовать собственные сценарии обработки трафика. Не обошлось и без модных облачных технологий. Новые коммутаторы поддерживают поддерживает фирменный стек Arista CloudVision, обеспечивающий удобное управление сетью, включая гибкую оркестрацию нагрузки, автоматизацию рабочих процессов, сбор телеметрии и многое другое. Обеспечена интеграция с программными решениями сторонних разработчиков, что упрощает внедрение сетей на базе Arista 7130 в уже существующую инфраструктуру. Подробности доступны на сайте Arista.
23.05.2022 [21:52], Алексей Степин
Учёные выяснили, что радиационный фон может влиять на ПЛИС, но защититься довольно простоВлияние ионизирующего излучения (радиации) на электронику бесспорно, и является одной из причин широкого внедрения технологии коррекции ошибок. Но если с памятью и процессорами всё более или менее понятно, то существует класс микросхем, для которого этот вопрос был малоисследован, во всяком случае, до недавнего времени. Это программируемые логические схемы, FPGA. Если обычный радиационный фон для единичных ПЛИС, очевидно, не представляет весомой угрозы, то что насчёт массивов из сотен тысяч работающих сообща микросхем такого типа? Вопрос не праздный ввиду роста популярности FPGA в качестве многофункциональных реконфигурируемых сопроцессоров в сфере HPC. Учёные из Университета Бригама Янга (Brigham Young University), штат Юта, США, дали ответ на этот вопрос. 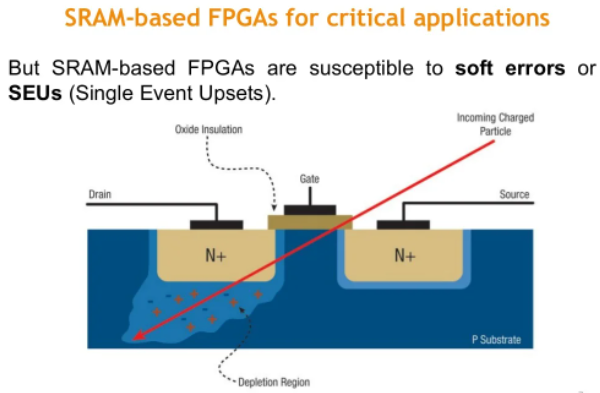
Пролетающая частица разряжает SRAM-ячейку. Источник: slideshare.net Полигоном стал ЦОД в Денвере, штат Колорадо, в котором одновременно работают до 100 тыс. ускорителей на базе ПЛИС. Сами эти микросхемы имеют т.н. «конфигурационную память», отвечающую за хранение реализованной в ПЛИС электронной схемы — путей, соединений, функциональных блоков. Поддержки ECC она не имеет, и как отметил ведущий исследователь Эндрю Келлер (Andrew Keller), проходящее через эту область ионизирующее излучение может отключать от схемы целые элементы, поскольку под его воздействием меняются хранимые в ячейках памяти значения. 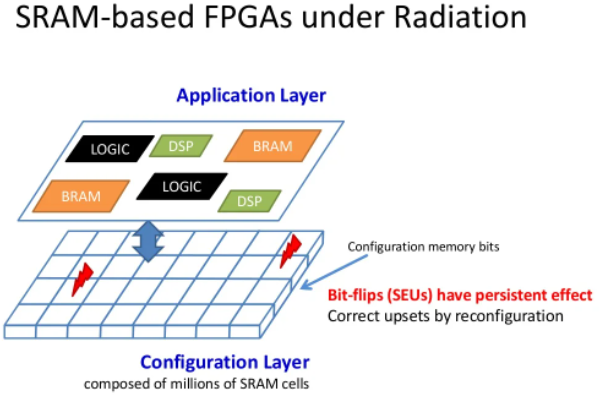
Влияние ионизирующего излучения на конфигурационную память создаёт источник «постоянной ошибки». Источник: slideshare.net В ЦОД масштаба от 100 тыс. FPGA изменение данных в конфигурационной памяти может происходить каждые полчаса, а незаметные повреждения данных (silent data corruption, SDC) накапливаться до 11 дней. Последнее представляет наибольшую угрозу, поскольку все эти дни ошибка накапливается — система всё ещё производит вычисления, но результаты могут быть неверны. Другая опасность — это полный выход ПЛИС из строя, но это заметят те, кто отвечает за работоспособность оборудования в ЦОД. 
FPGA бывают и в защищённом от радиации исполнении. Источник: militaryaerospace.com Методы защиты, впрочем, довольно просты: механика коррекции ошибок Single Event Upsets (SEU) реализована во всех современных FPGA; есть также механизм периодической перезаписи конфигурации (scrubbing) в случае обнаружения ошибки, который может снизить вероятность повреждения данных в 3–22 раза. К сожалению, большая часть решений на базе FPGA последний механизм не задействует, хотя, как отметили исследователи, крупные гиперскейлеры пользуются им чаще. Также предполагалось, что по мере освоения более тонких техпроцессов возможно учащение мультибитных ошибок, поскольку пролетающая частица может задеть не одну ячейку памяти, а сразу несколько. Однако эксперименты команды Келлера опровергают это предположение. По всей видимости, производители ПЛИС знают об этом эффекте и стараются защитить от него новые продукты. Существуют также FPGA в защищённом исполнении, которые, как правило, применяются в военной и аэрокосмической технике.
19.05.2022 [19:50], Алексей Степин
Представлен FPGA-модуль AMD Xilinx Kria KR260 для быстрой разработки робототехникиСемейство модулей Xilinx Kria появилось ещё весной прошлого года, позиционировались новинки в качестве платформы для быстрой разработки периферийных (edge) устройств, особенно связанных с системами машинного зрения. Вчера же был представлен новый модуль Kria KR260, предназначенный специально для робототехники. По сравнению с моделью KV260 базовая плата новинки имеет расширенные возможности, особенно в части сетевой подсистемы. Основой по-прежнему является SoM Kria K26 на базе FPGA Zynq UltraScale+, но в отличие от KV260 новая KR260 имеет не один, а два 240-контактных разъёма. Количество 1GbE-интерфейсов подросло до четырёх, причём два разъёма поддерживают индустриальную версию, а пятый Ethernet-интерфейс (10GbE) выполнен в форм-факторе SFP+. Есть поддержка TSN. Другое важное отличие — поддержка высокоскоростных модулей машинного зрения SLVS-EC (до 860 Мпикс/с) против обычных с интерфейсом MIPI. 
Источник: AMD Xilinx Также стоит отметить наличие большого количества разъёмов как для подключения сенсорных систем, например, лидара, так и для силовых ключей, обслуживающих приводы. Платформа реализует полностью предсказуемую внутреннюю сеть, а также может работать в составе кластера из нескольких плат KR260. Имеются развитые аппаратные средства для разгрузки процессоров от вспомогательных задач, вроде планировки движения или объединения сенсоров. 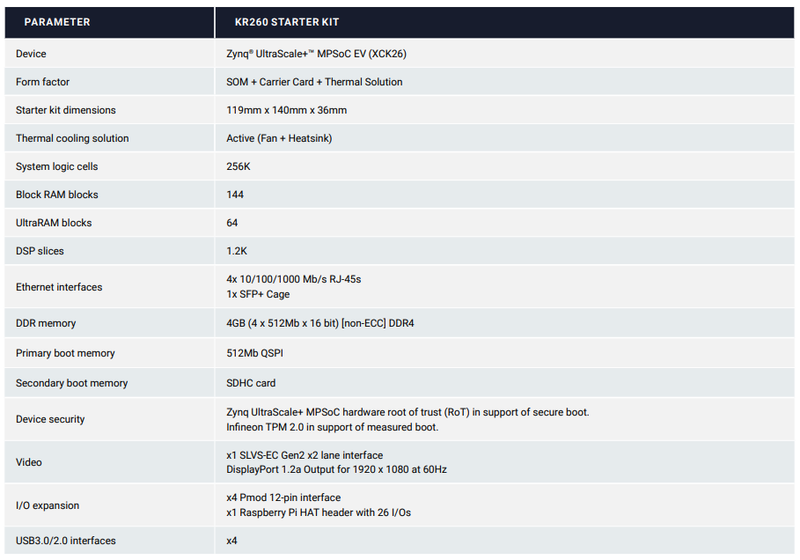
Характеристики платформы Kria KR260. Источник: AMD Xilinx Стоимость новинки довольно высока: сам модуль K26 стоит $300 в базовой версии или $420 в защищённом исполнении (от -40 до +100 °C), а плата KR260 обойдётся ещё в $349. Но это даст покупателю законченную и мощную систему, имеющую массу IO-портов и поддерживающую обработку видео сразу с нескольких HD-камер. Причём для неё уже есть магазин готовых приложений. Похоже, AMD всерьёз нацелилась на рынок робототехнических платформ, где собирается конкурировать с решениями NVIDIA Jetson.
13.05.2022 [21:41], Алексей Степин
AMD поможет Meta✴ развернуть открытую 5G-инфраструктуру на базе решений XilinxПриобретение активов Xilinx открыло для AMD новые горизонты, порой неожиданные. Так, компания недавно заключила соглашение с Meta✴, в рамках которого поможет разработать беспроводную 5G-инфраструктуру на базе Open RAN в рамках проекта Evenstar. Сама Meta✴ заинтересована в том, чтобы подключить к проекту свой метавселенной как можно больше пользователей, в том числе и тех, кто не имеет сегодня качественного доступа в Сеть. Сочетание технологий AMD/Xilinx поможет ей в этом начинании. В арсенале Xilinx как раз есть подходящая FPGA-матрица RFSoC DFE из серии Zynq UltraScale+, которая уже используется в составе ускорителей T1, созданных специально для нужд телеком-индустрии. Эта ПЛИС позволяет реализовать достаточно производительную для поддержи 5G-радиочасти и в то же время гибкую логику, причём в многоканальном режиме. Сейчас у AMD есть полный набор микрочипов и ПЛИС, необходимых для построения универсальных базовых станций 4G/5G. 
Изображение: AMD/Xilinx Однако это далеко не единственная инициатива Meta✴ в области повышения доступности широкополосного интернета. Помимо крупных инвестиций в подводные и наземные волоконно-оптически линии связи, компания разрабатывает самоорганизующеся 5G-сети Terragraph, которые, в частности, уже появились на Аляске, и развивает проект по созданию автономного робота Bombyx, способного самостоятельно прокладывать оптоволокно по линиям электропередач. Компания сейчас настолько увлечена идеей метавселенной, что даже заявила о необходимости выработки новых стандартов сетевой инфраструктуры ближайшего будущего. |
|

