Материалы по тегу: databricks
|
28.03.2024 [22:01], Владимир Мироненко
Databricks представила открытую LLM DBRX, превосходящую GPT-3.5 TurboАмериканский стартап в сфере аналитики больших данных и машинного обучения Databricks объявил о выходе DBRX, большой языковой модели (LLM) общего назначения, которая, по его словам, превосходит в стандартных бенчмарках все существующие LLM с открытым исходным кодом, а также некоторые проприетарные ИИ-модели. Стартап заявил, что открывает исходный код модели, чтобы побудить пользователей отказаться от коммерческих альтернатив. Он отметил, что согласно исследованию Andreessen Horowitz LLC, почти 60 % лидеров в области ИИ-технологий заинтересованы в увеличении использования или переходе на open source, если открытые модели после тюнинга примерно соответствуют по производительности проприетарным моделям. 
Источник изображений: Databricks «Я считаю, что самые ценные данные хранятся внутри предприятий. ИИ как бы исключён из этих сфер, поэтому мы пытаемся реализовать это с помощью моделей с открытым исходным кодом», — цитирует ресурс SiliconANGLE заявление гендиректора Databricks Али Годси (Ali Ghodsi) на брифинге с журналистами. По словам Годси, лучше всего DBRX подходит для сфер, где критически важны управление и безопасность, например, для финансовых услуг и здравоохранения, или там, где важен тон ответов, например, в области самообслуживании клиентов. 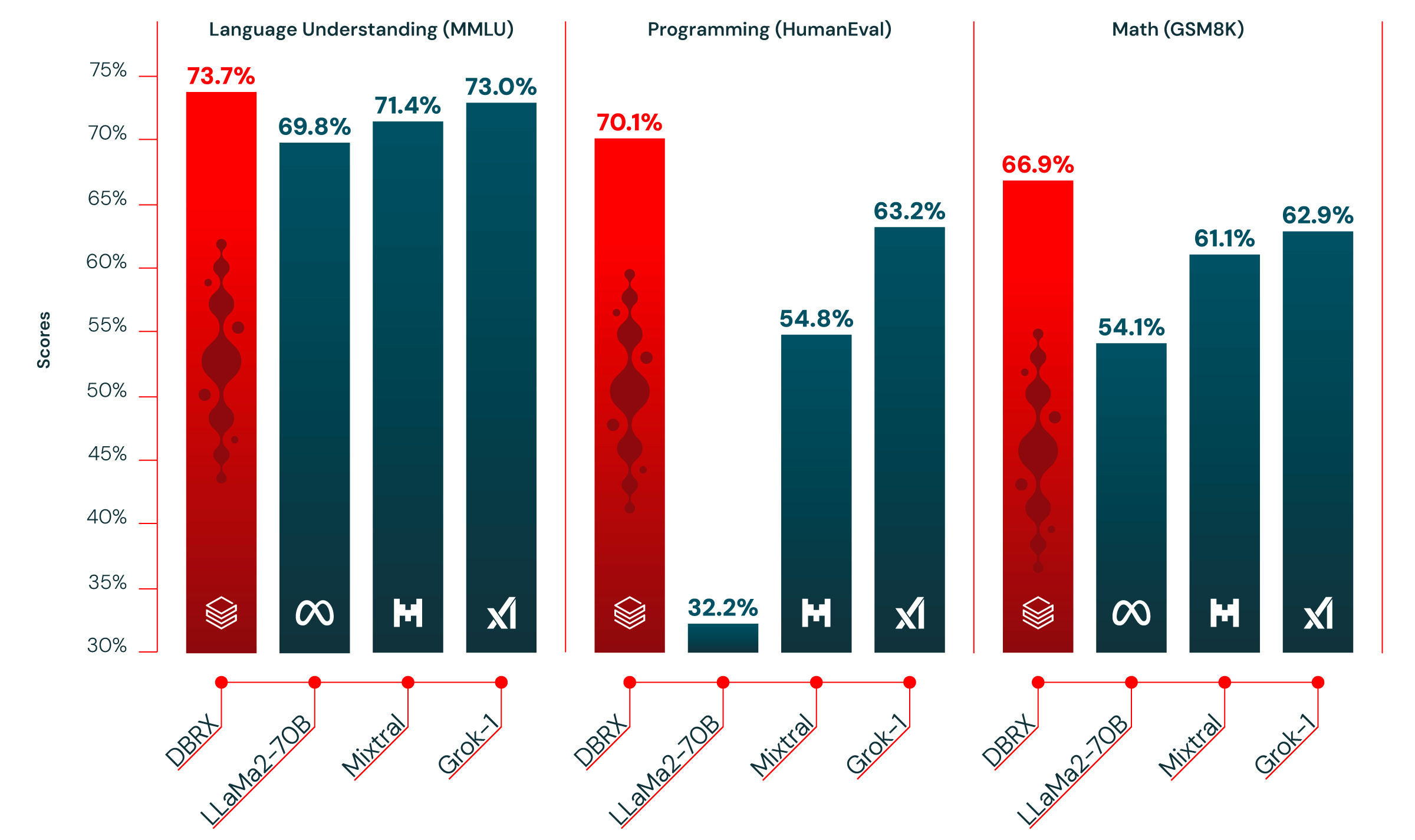 DBRX использует архитектуру Mixture of Experts (MoE, набор экспертов), которая делит процесс обучения между несколькими специализированными «экспертными» подсетями. Каждый «эксперт» владеет определёнными навыками, а исходный запрос оптимальным образом распределяется между «экспертами». Вице-президент Databricks по генеративному ИИ, перешедший в компанию вместе с приобретением MosaicML, соучредителем которой он был, заявил, что MoE работает даже лучше человека. 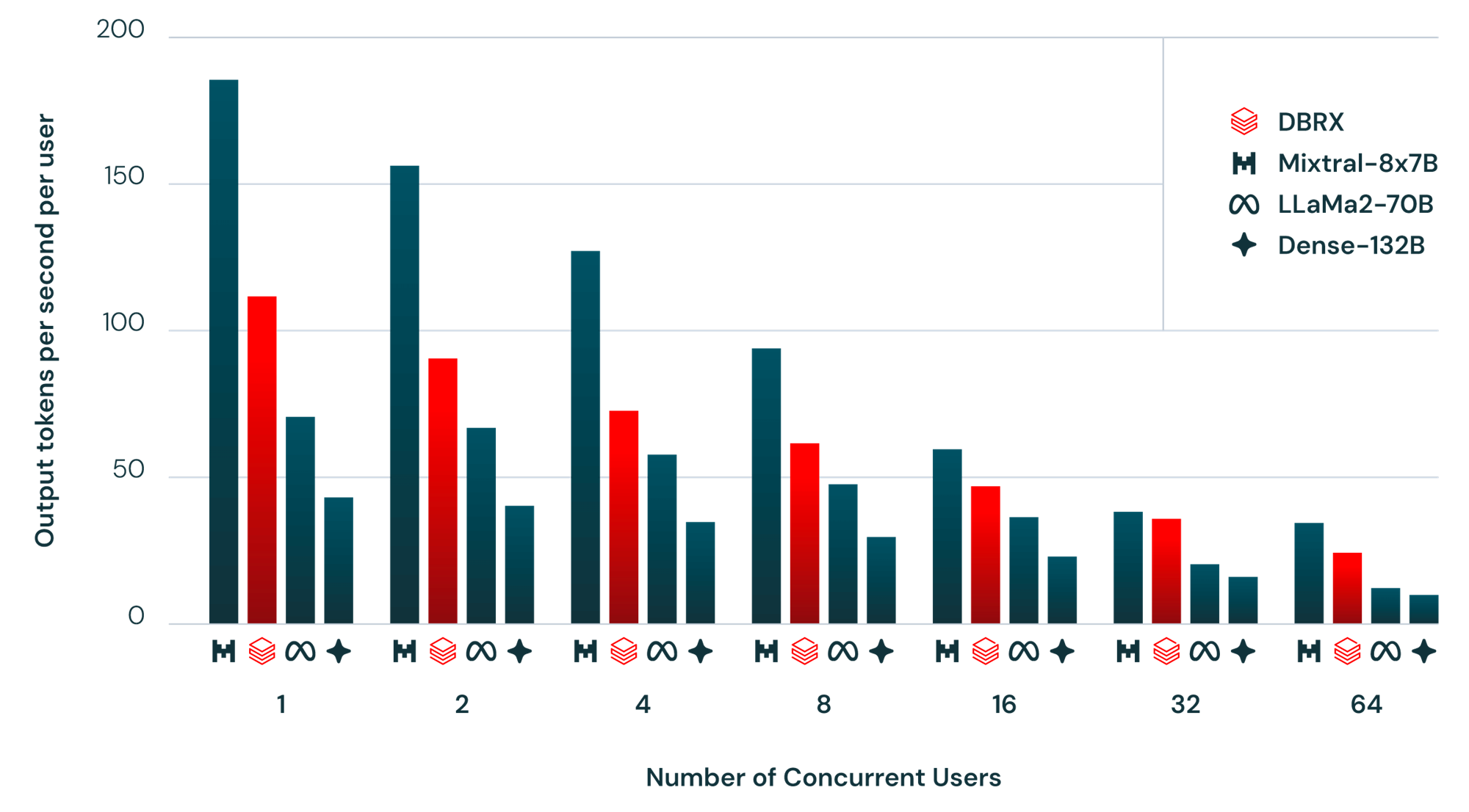 Хотя DBRX с 132 млрд параметром почти в два раза больше Llama 2, она всё равно вдвое быстрее. Также сообщается, что DBRX превзошла существующие LLM с открытым исходным кодом Llama 2 70B и Mixtral-8x7B (тоже MoE), а также запатентованную GPT-3.5 Turbo в тестах на понимание языка, программирование, математику и логику. Обучение модели на общедоступных и лицензированных источниках данных в течение двухмесячного периода обошлось Databricks всего в $10 млн с использованием 3 тыс. ускорителей NVIDIA H100. По словам компании, при создании приложений генеративного ИИ модель DBRX можно использовать вместе с Databricks Mosaic AI, набором унифицированных инструментов для создания, развёртывания и мониторинга моделей ИИ. Базовая модель DBRX Base и продвинутая модель DBRX Instruct доступны по открытой лицензии для исследований и коммерческого использования на GitHub и Hugging Face. Разработчики могут уже сегодня создавать свои варианты DBRX на основе собственных данных на платформе Databricks.
16.09.2023 [21:34], Сергей Карасёв
Стартап Databricks привлёк ещё $500 млн, что повысило капитализацию компании до $43 млрдСтартап Databricks, разработчик платформы машинного обучения, анализа и обработки данных, сообщил о проведении раунда финансирования Series I: на развитие привлечено дополнительно $500 млн. Таким образом, на сегодняшний день общий объём инвестиций в эту компанию превысил $4 млрд. Databricks предоставляет озеро данных, которое предприятия могут использовать для хранения, организации и анализа больших объемов информации. Стартап также помогает заказчикам в развёртывании собственных приложений на базе генеративного ИИ. Компания основана в 2013 году создателями Apache Spark. 
Источник изображения: Gabby Jones / Bloomberg Отмечается, что Databricks быстро наращивает выручку: по итогам II четверти текущего финансового года, которая была закрыта 31 июля, показатель преодолел знаковый рубеж в $1,5 млрд — это более чем на 50 % превосходит прошлогодний результат. В глобальном масштабе решения Databricks применяют свыше 10 тыс. организаций, включая более половину компаний из списка Fortune 500. Раунд финансирования Series I проведён под руководством T. Rowe Price Associates. В программе также приняли участие Andreessen Horowitz, Baillie Gifford, ClearBridge Investments, Counterpoint Global (Morgan Stanley), Fidelity Management & Research Company, Franklin Templeton, GIC, Octahedron Capital, Tiger Global, Capital One Ventures, Ontario Teachers' Pension Plan и NVIDIA. Прошлый раунд финансирования Databricks был завершён в 2021 году: тогда стартап получил $1,6 млрд, а его рыночная стоимость достигла $38 млрд. Теперь же капитализация оценивается в $43 млрд при стоимости акций на уровне $73,5.
27.06.2023 [16:56], Владимир Мироненко
Databricks купила разработчика генеративного ИИ MosaicML за $1,3 млрдСтартап Databricks, разработчик платформы машинного обучения, анализа и обработки данных, объявил о приобретении компании-разработчика решений в области генеративного ИИ MosaicML Inc. С помощью разработанных MosaicML языковых моделей компании смогут обучать и выполнять точную настройку генеративных ИИ-моделей на основе собственных данных с высоким качеством и низкой стоимостью, а технологии оптимизации обучения моделей MosaicML помогут снизить затраты. MosaicML наиболее известна своим собственным семейством больших языковых моделей (LLM) MPT, с более чем 3,3 млрд загрузок модели MPT-7B. Семейство LLM компании с открытым исходным кодом основано на архитектуре MPT-7B, построенной с 7 млрд параметров и контекстным окном на 64 тыс. токенов. На днях MosaicML выпустила модель MPT-30B с 30 млрд параметров, которая гораздо мощнее MPT-7B и превосходит по качеству модель OpenAI GPT-3 (175 млрд параметров). 
Источник изображения: MosaicML MosaicML сообщила, что размер MPT-30B был специально подобран для развёртывания всего на одном ускорителе — либо NVIDIA A100 80 Гбайт (16-бит точность), либо A100 40 Гбайт (8-бит точность). По словам MosaicML, другие сопоставимые LLM, такие как Falcon-40B, имеют большее количество параметров и не могут обслуживаться на одном ускорителе, что увеличивает минимальную стоимость системы инференса. Платформа Databricks Lakehouse в сочетании с технологиями MosaicML предложит клиентам простой, быстрый и экономичный способ сохранить контроль над данными, а также обеспечить их безопасность и защитить правf собственности. Размещая модели в Databricks Lakehouse, компании смогут адаптировать их к конкретным корпоративным данным и безопасно развёртывать их. Использование обслуживаемых моделей, таких как от OpenAI, может привести к утечке данных и другим рискам. Это особенно важно для строго регулируемых отраслей — модель и данные должны оставаться вместе в изолированном окружении. 
Источник изображения: Databricks Кроме того, решения MosaicML обеспечивают в 2–7 раз более быстрое обучение моделей по сравнению со стандартными подходами, предлагая при этом линейное масштабирование. Компания утверждает, что модели с несколькими миллиардами параметров теперь можно обучить за часы, а не за дни. Согласно пресс-релизу, при применении интегрированной платформы Databricks и MosaicML обучение и использование LLM будет стоить тысячи долларов, а не миллионы. «Теперь Databricks может расширить свою платформу для создания, обучения и размещения традиционных моделей машинного обучения на большие языковые модели, — заявил Джастин ДеБрабант (Justin DeBrabant), старший вице-президент ActionIQ Inc. — Это означает, что Databricks предлагает продукты и услуги на платформе Lakehouse. которые простираются от ETL до аналитики SQL, пользовательского машинного обучения, а теперь и до размещённых LLM».
13.04.2023 [21:03], Владимир Мироненко
Databricks выпустила полностью бесплатную и открытую ИИ-модель Dolly для создания аналогов чат-бота ChatGPTПоставщик решений для аналитики больших данных и машинного обучения Databricks (США) объявил о выходе Dolly 2.0, модели генеративного искусственного интеллекта (ИИ) следующего поколения с открытым исходным кодом, которая имеет сходные с ChatGPT (OpenAI) возможности. Dolly 2.0, как и предшественница Dolly, вышедшая пару недель назад, использует меньший набор данных, чем имеется у большинства больших языковых моделей (LLM). Dolly имела 6 млрд параметров, а у Dolly 2.0 их вдвое больше — 12 млрд. Для сравнения, у GPT-3 — 175 млрд параметров. Сообщается, что Dolly 2.0 была построена на высококачественном наборе данных. Отличительной особенностью новых моделей генеративного ИИ является возможность использовать собственный набор данных обучения для создания связных предложений и ответов на вопросы пользователей. И Dolly 2.0 может делать это, даже несмотря на намного меньший объём исходных данных, чем у моделей OpenAI. Это, в свою очередь, позволяет использовать модель на собственных серверах без необходимости делиться данными со сторонними организациями. Источник: Databricks «Мы считаем, что такие модели, как Dolly, помогут демократизировать LLM, превратив их из того, что могут себе позволить очень немногие компании, в товар, которым может владеть каждая компания и который можно настраивать для улучшения своих продуктов», — заявила Databricks. Руководитель Databricks в комментарии изданию SiliconANGLE подчеркнул, что предприятия «могут монетизировать Dolly 2.0». 
Источник: Databricks Databricks предлагает Dolly 2.0 под лицензией Creative Commons, с полностью открытыми исходным кодом и набором данных для обучения databricks-dolly-15k, который содержит 15 тыс. высококачественных пар запросов и ответов, созданных человеком. Всё это можно свободно использовать, изменять и дополнять, а также задействовать в коммерческих проектах, ничего никому не платя. Исследователи и разработчики могут получить доступ к Dolly 2.0 на Hugging Face и GitHub. Как утверждает Databricks, в настоящее время Dolly 2.0 является единственной моделью, которая не имеет лицензионных ограничений. Другие модели, включая Alpaca, Koala, GPT4All и Vicuna, нельзя использовать в коммерческих целях из-за использования обучающих данных, предоставленных им с определёнными условиями. Исходный вариант Dolly был обучен на данных Stanford Alpaca с использованием API OpenAI, так что её нельзя было использовать в коммерческих целях, так как в этом случае лицензии запрещают создавать конкурирующие модели. Поэтому Databricks решила создать собственную модель, используя только ответы её сотрудников. Задания для них включали, например, просьбы высказаться на тему «Почему людям нравятся комедии?», обобщить информации из Википедии, написать любовные письма, стихов и даже песни. |
|

