Как и было обещано несколько лет назад, основным «строительным блоком» для графики и ускорителей Intel станут ядра Xe, которые можно будет гибко объединять и сочетать с другими аппаратными блоками для получения заданной производительности и функциональности. Компания уже анонсировала первые «настоящие» дискретные GPU серии Arc, а на Intel Architecture Day она поделилась подробностями о серверных ускорителях Xe HPC и Ponte Vecchio.

Основой Xe HPC является вычислительное ядро Xe Core, которое включает по восемь векторных и матричных движков для данных шириной 512 и 4096 бит соответственно. Они делят между собой L1-кеш объёмом 512 Кбайт, с которым можно общаться на скорости 512 байт/такт.

Заявленная производительность для векторного движка (бывший EU), ориентированного на «классические» вычисления, составляет 256 операций/такт для FP32 и FP64 или 512 — для FP16. Матричный движок нужен скорее для ИИ-нагрузок, поскольку работает только с данными TF32, FP16, BF16 и INT8 — 2048, 4096, 4096 и 8192 операций/такт соответственно. Данный движок работает с инструкциями XMX (Xe Matrix eXtensions), которые в чём-то схожи с AMX в Intel Xeon Sapphire Rapids.

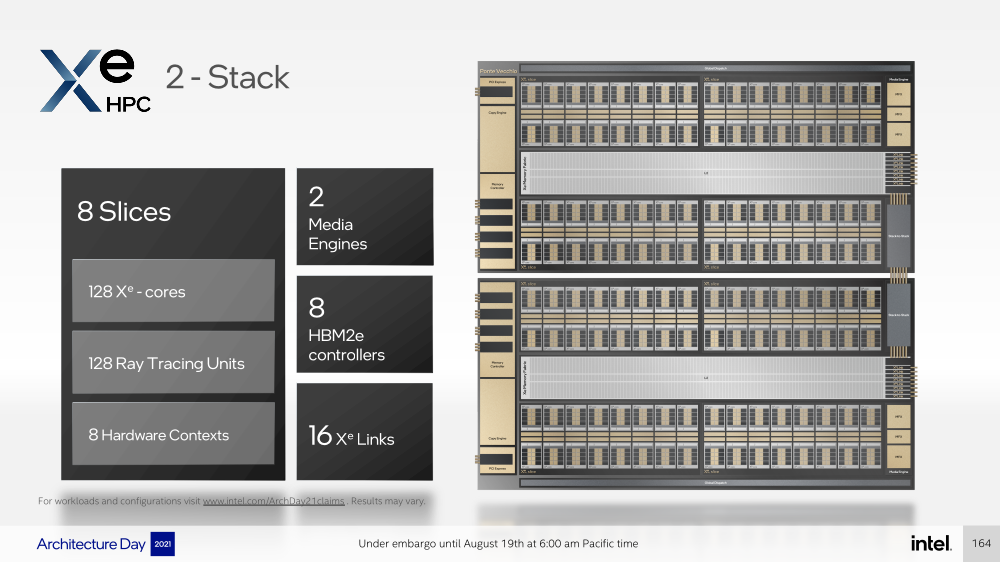
Отдельные ядра объединяются в «слайсы» (slice) — по 16 Xe-Core в каждом, которые дополнены 16 блоков аппаратной трассировки лучей. Именно слайс является базовым функциональным блоком. Он изготавливается на TSMC по 5-нм техпроцессу в рамках инициативы Intel IDM 2.0. Слайсы объединяются в стеки — по 4 шт. в каждом.

Стек включает также базовую (Base) «подложку» (или тайл), четыре контроллерами памяти HBM2e (сама память вынесена в отдельные тайлы), общим L2-кешем объёмом 144 Мбайт, один медиа-движок с аппаратными кодеками, а также тайл Xe Link и контроллер PCIe 5. Base-тайл изготовлен по техпроцессу Intel 7 и использует EMIB для объединения всех блоков.
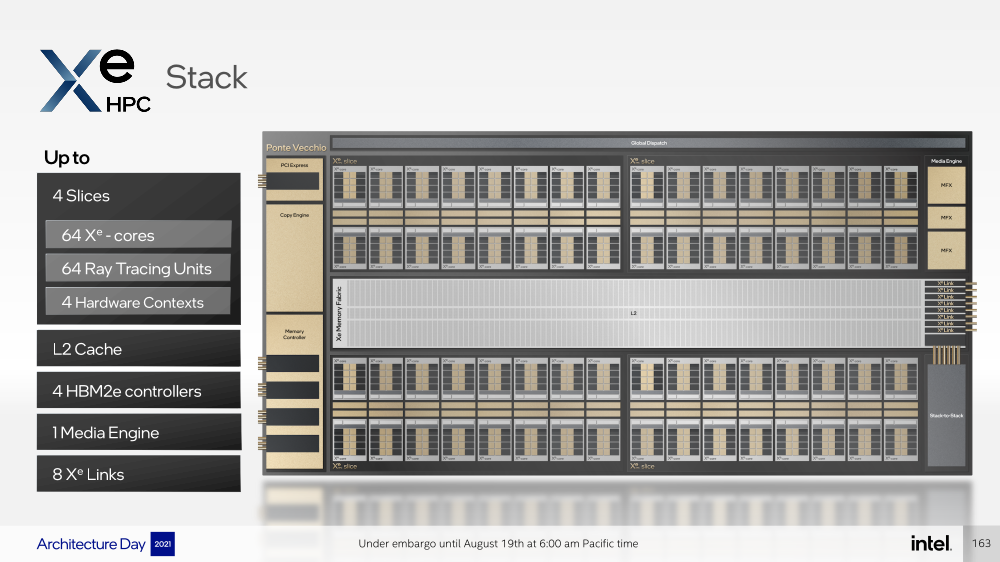
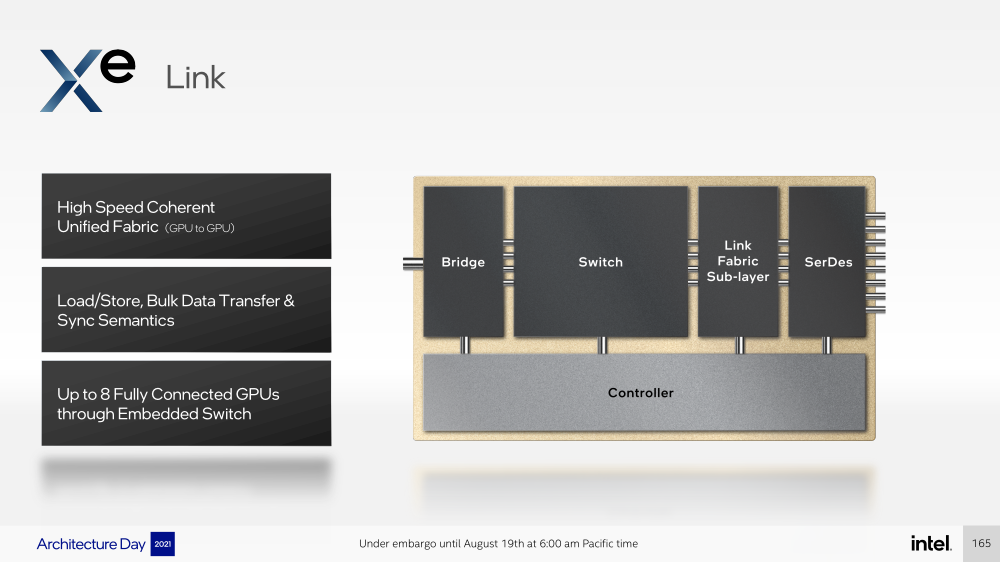
Тайлы Xe Link, изготавливаемые по 7-нм техпроцессу TSMC, включают 8 интерфейсов для стеков/ускорителей вкупе с 8-портовыми коммутатором и используют SerDes-блоки класса 90G. Всё это позволяет объединить до 8 стеков по схеме каждый-с-каждым, что, в целом, напоминает подход NVIDIA, хотя у последней NVSwitch всё же (пока) является внешним компонентом.

В самом ускорителе в зависимости от конфигурации стеков может быть один или два. В случае Ponte Vecchio их как раз два, и Intel приводит некоторые данные о его производительности: более 45 Тфлопс в FP32-вычислениях, более 5 Тбайт/с пропускной способности внутренней фабрики памяти и более 2 Тбайт/с — для внешних подключений. Для сравнения, у NVIDIA A100 заявленная FP32-производительность равняется 19,5 Тфлопс, а AMD Instinct MI100 — 23,1 Тфлопс.
Также Intel показала результаты бенчмарка ResNet-50 в обучении и инференсе: 3400 и 43000 изображений в секунду соответственно. Эти результаты являются предварительными, поскольку получены не на финальной версии «кремния». Но надо учитывать, что Ponte Vecchio есть ещё одно преимущество — отдельный Rambo-тайл с дополнительным сверхбыстрым кешем, который, вероятно, можно рассматривать в качестве L3-кеша.

В целом, Ponte Vecchio — это один из самых сложны чипов на сегодняшний день. Он объединяет с помощью EMIB и Foveros 47 тайлов, изготовленных по пяти разным техпроцессам, а общий транзисторный бюджет превышает 100 млрд. Данные ускорители будут доступны в форм-факторе OAM и виде готовых плат с четырьмя ускорителями на борту (на ум опять же приходит NVIDIA HGX). И именно такие платы в паре с двумя процессорами Sapphire Rapids войдут в состав узлов суперкомпьютера Aurora. Ещё одной машиной, использующей связку новых CPU и ускорителей Intel станет SuperMUC-NG (Phase 2).

Официальный выход Ponte Vecchio запланирован на 2022 год, но и выход следующих поколений ускорителей AMD и NVIDIA, с которыми и надо будет сравнивать новинки, тоже не за горами. Пока что Intel занята не менее важным делом — развитием программной экосистемы, основой которой станет oneAPI, набор универсальных инструментов разработки приложений для гетерогенных (CPU, GPU, IPU, FPGA и т.д.) приложений, который совместим с оборудованием AMD и NVIDIA.
Источник:

